Loģistiskā regresija
Loģistiskā regresija izveido modeli, kas prognozē varbūtību, ka ieraksts pieder noteiktai klasei.
Piemēram, rūpnīcas iekārtu datu kopā ir iespējams prognozēt iekārtas atteices varbūtību 2 nedēļu laikā bez steidzamas apkopes. Tas palīdz komandai koncentrēties uz iekārtām, kurām nepieciešama vispromptākā uzmanība. Citi piemēri ietver klientu atbiruma, darbinieku mainības, klienta intereses prognozēšanu konkrētā jomā. Iespējas ir bezgalīgas.
- Sāciet darbu ar TableTorch
- Dārgu transportlīdzekļu identificēšana
- Loģistiskās regresijas precizēšana
- Stratifikācija
- Skatīt arī
Loģistiskā regresija ir īpaša lineārās regresijas veids. Tā prasa, lai atkarīgais mainīgais (etiķete) būtu vai nu 1, vai 0, norādot, vai ieraksts pieder klasei vai nē. Tā izveido lineāru modeli, kura etiķete ir transformēta ar loģistisko funkciju.
Loģistiskā funkcija ir definēta šādi:
![]()
Novērtēšanas laikā šī formula tiek pielietota ar argumentiem
L = 1
k = 1
x0 = 0
kur x ir lineārā modeļa novērtējuma rezultāts. Tādējādi loģistiskā modeļa prognozes pieder kopai (0; 1) un var tikt interpretētas kā varbūtības, ka rinda pieder klasei.

TableTorch nodrošina to pašu uzlaboto funkciju kopumu loģistisko regresiju veikšanai, kādu tas dara lineārajām regresijām. Lai iegūtu vairāk informācijas par dažādām apmācības un izlases veidošanas opcijām, skatiet lapu par regresiju precizēšanu.
Turpmākajās sadaļās mēs izveidosim loģistisku modeli, prognozējot, vai kolonna selling_price no transportlīdzekļu datu kopas pārsniedz 1 025 000, kas ir šīs kolonnas 90. percentīle.
Sāciet darbu ar TableTorch
- Instalējiet TableTorch Google izklājlapām, izmantojot Google Workspace Marketplace. Vairāk informācijas par sākotnējo iestatīšanu.
- Noklikšķiniet uz TableTorch ikonas
 Google izklājlapu labās puses panelī.
Google izklājlapu labās puses panelī.
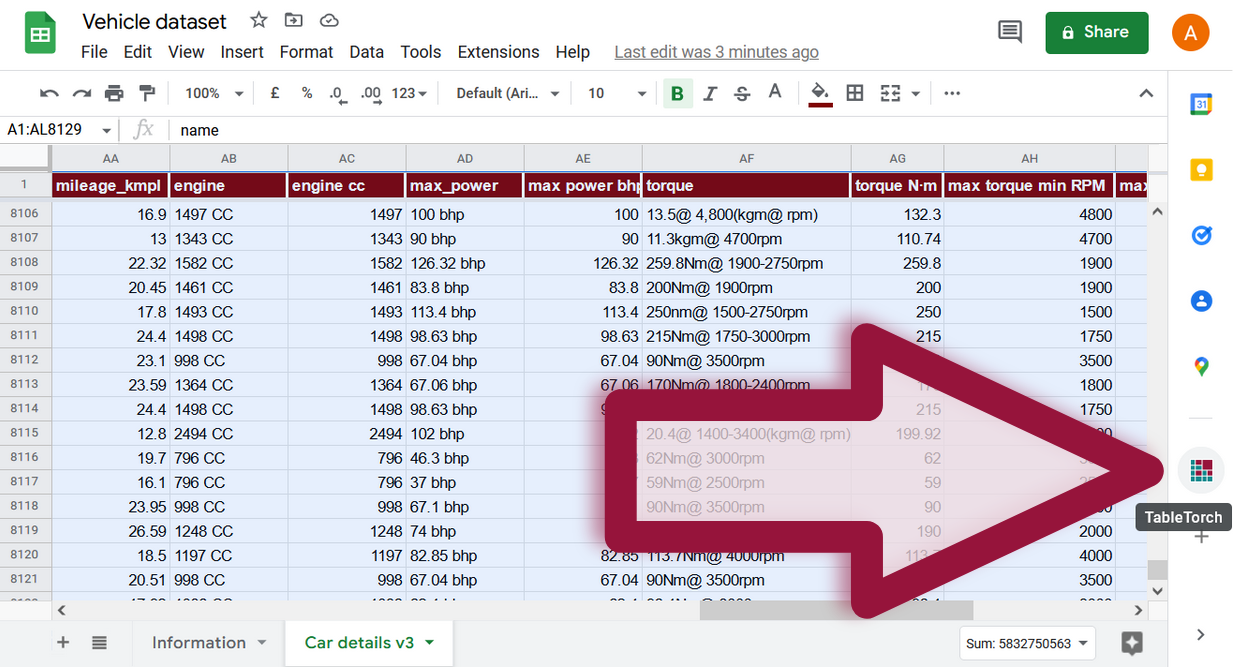
Dārgu transportlīdzekļu identificēšana
Pievienojiet kolonnu is expensive pēc selling_price ar formulu
=IF(M2 > 1025000, 1, 0)
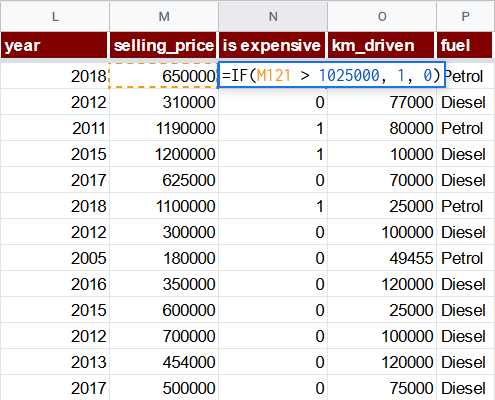
Atlasiet visu lapas diapazonu un noklikšķiniet uz izvēlnes elementa Loģistiskā regresija TableTorch izvēlnē.
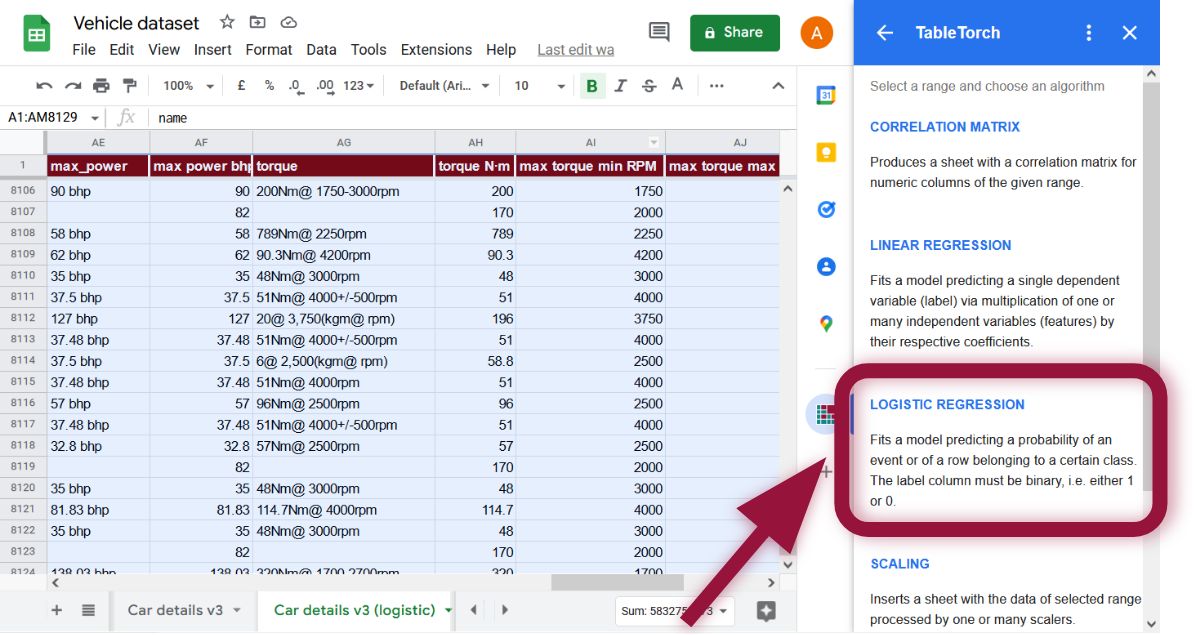
Iestatiet kolonnu is expensive kā etiķeti. Papildus noņemiet atzīmi kolonnai selling_price pazīmju sarakstā. Mūsu etiķete ir atkarīga no tās, tāpēc to nevajadzētu izmantot regresijā.
Noklikšķiniet uz Apmāciet modeli, lai veiktu regresiju. Drīz parādīsies regresijas kopsavilkums, kam jāizskatās apmēram šādi:
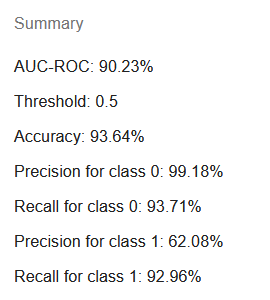
Ievērojiet, ka rādītāji atšķiras no tiem, kas parādās lineārajām regresijām. Tas ir pareizi. Nav daudz jēgas novērtēt RMSE vai R², jo mēs vairāk interesējamies par klases identificēšanas precizitāti, nevis par precīzu atlikumu starp prognozi un etiķetes 1 vai 0 vērtību.
AUC-ROC (area under curve - receiver operating characteristic, laukums zem ROC līknes) ir bieži izmantots rādītājs, lai novērtētu modeļa prognozes pareizības varbūtību.
Slieksnis pēc noklusējuma vienmēr ir 0,5 un ir norādīts kopsavilkumā, jo šādi rādītāji kā pareizība, precizitāte un sensitivitāte ir atkarīgi no tā. Bināriem klasifikatoriem, kas balstīti uz loģistiskiem modeļiem, tiek piešķirta klase rindām, kurām prognoze ir lielāka vai vienāda ar slieksni.
Vēlākā šī dokumenta sadaļā mēs pārskatīsim detalizētu loģistiskās regresijas kopsavilkuma lapu. Tā var palīdzēt mums izvēlēties atšķirīgu slieksni, pamatojoties uz mūsu prioritātēm.
Pareizība norāda rindu daļu, kurām modelis spēja dot pareizo atbildi.
Precizitāte klasei 0 un precizitāte klasei 1 parāda to rindu procentuālo daļu, kuras tika pareizi prognozētas piederot noteiktai klasei. Piemēram, ja precizitāte klasei 1 ir 62%, tas nozīmē, ka 38% rindu, kas tika prognozētas piederot klasei 1, patiesībā tai nepiederēja, norādot uz ievērojamu viltus pozitīvo rādītāju.
Sensitivitāte klasei 0 un sensitivitāte klasei 1 nozīmē to rindu daļu, kuras tika novērotas būt noteiktā klasē un arī modeļa prognozētas būt šajā klasē. Piemēram, ja sensitivitāte klasei 1 ir 93%, tad 7% rindu, kas tika novērotas piederot klasei 1, saņēma neprecīzu prognozi.
Noklikšķiniet uz pogas Ievietojiet prognozēšanas kolonnu. Izveidotās kolonnas vērtība katrai rindai norādīs modeļa novērtējumu par varbūtību, ka šim transportlīdzeklim ir selling_price lielāks par 1 025 000.
Ar šo varbūtību tagad ir iespējams ievietot binārā klasifikatora kolonnu. Vienīgais svarīgais parametrs, kas vēl jānosaka, ir slieksnis, pie kura rindai jāpiešķir klase is expensive:
=IF(AN2 >= 0.5, 1, 0)
Skaitlis 0,5 iepriekš minētajā formulā ir slieksnis. 0,5 bieži vien dod līdzsvarotāko modeļa veiktspēju sensitivitātes, precizitātes un pareizības ziņā. Tomēr, atkarībā no mūsu mērķiem, atšķirīga vērtība var būt piemērotāka.
Noklikšķināsim uz pogas Pievienojiet kopsavilkuma lapu un pārskatīsim regresijas detaļas.

Papildus konstantei un koeficientiem, kas ir jebkuras lineārās regresijas kopsavilkumā, loģistiskās regresijas kopsavilkuma lapa satur precizitātes, sensitivitātes un pareizības raksturlielumu tabulu dažādos sliekšņa līmeņos.
Piemēram, ja mēs vēlētos, lai modelis būtu precīzāks un izvairītos no kļūdainas klases 1 piešķiršanas rindām, mēs varētu apsvērt sliekšņa 0,87 izmantošanu 0,5 vietā. Šajā punktā precizitāte sasniedz 90% 62% vietā pie sliekšņa 0,5. Tomēr mēs arī redzam, ka pie sliekšņa 0,87 sensitivitāte nokrītas līdz nedaudz zem 80%, kas ir daudz mazāk nekā gandrīz 93%, ko var sasniegt pie sliekšņa 0,5.
Tāpat, izvēloties zemāku slieksni, piemēram, 0,13, var ievērojami uzlabot klasifikatora sensitivitāti, sasniedzot gandrīz 99%, par cenu precizitātes samazināšanai līdz aptuveni 40%.
Tomēr ir iespējams veids, kā sasniegt vēlamo precizitātes vai sensitivitātes līmeni bez otras raksturlieluma ziedošanas: izveidot labāku modeli.
Loģistiskās regresijas precizēšana
Katru iespējamo opciju, kas apspriesta lapā par lineāro regresiju precizēšanu, var pielietot arī loģistiskajām regresijām. Zem pārsega process ir tāds pats.
Izmēģināsim šādus precizēšanas soļus:
- Piemērojiet pazīmju inženieriju un kolonnu izslēgšanas tehniku, kas aprakstīta lapā regresiju precizēšana.
- Ieslēdziet 3 reižu savstarpēja validācija.
-
Pievienojiet vairāk ražotāju identificējošas kolonnas tādā pašā veidā, kā mēs darījām transportlīdzekļu datu kopas sagatavošanas laikā.
-
Volvo
=IF(ISNUMBER(FIND("Volvo", A2)), 1, 0) - BMW
=IF(ISNUMBER(FIND("BMW", A2)), 1, 0) - Audi
=IF(ISNUMBER(FIND("Audi", A2)), 1, 0) - Mercedes-Benz
=IF(ISNUMBER(FIND("Mercedes-Benz", A2)), 1, 0) - Lexus
=IF(ISNUMBER(FIND("Lexus", A2)), 1, 0) - Jaguar
=IF(ISNUMBER(FIND("Jaguar", A2)), 1, 0) - Jeep
=IF(ISNUMBER(FIND("Jeep", A2)), 1, 0) - Land Rover
=IF(ISNUMBER(FIND("Land Rover", A2)), 1, 0) - Volkswagen
=IF(ISNUMBER(FIND("Volkswagen", A2)), 1, 0)
-
-
Pievienojiet vairāk atvasinātu pazīmju:
- perceived wear
=Z2 / (Y2 / MAX($Y$2:$Y$8129))
kur Z ir kolonna km_driven un Y ir kolonna average price of year.
- depreciated torque N·m
=AU2 * Y2 / MAX($Y$2:$Y$8129)
kur AU ir kolonna torque N·m un Y ir kolonna average price of year.
- perceived wear
- Atlasiet visu diapazonu un atveriet rīku Loģistiskā regresija TableTorch.
- Izmantojiet stratificētu vienmērīgu nejaušu izlases veidošanu ar year stratum kā slāņa kolonnu.
- Noņemiet atlasi kolonnām *year, selling_price, is expensive, km_driven, petrol, max power bhp, engine cc, torque N·m, max torque min RPM** no pazīmju saraksta.
- Noklikšķiniet uz Apmāciet modeli.
Izveidotajam modelim būs šāds kopsavilkums:
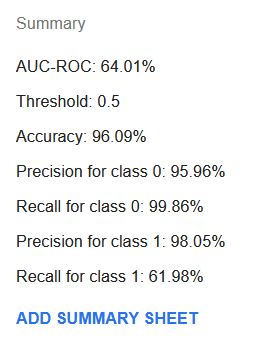
Lai gan AUC-ROC ir kļuvis diezgan zemāks pie 64%, pareizība, sensitivitāte klasei 0 un precizitāte klasei 1 ir ievērojami uzlabojušies. Sensitivitāte klasei 1 ir krities ievērojami līdz tikai 62%. Tomēr, ja mēs aplūkojam apmācības kopsavilkuma lapu, ir iespējams atrast slieksni, piemēram, 11%, kur sensitivitāte ir 83%, bet precizitāte ir 89% un pareizība ir 97%.
Jaunais modelis, iespējams, ir labāks nekā tas, kas tika sasniegts ar noklusējuma iestatījumiem. Tomēr tas joprojām neizskatās pēc būtiska uzlabojuma. Varbūt datu kopai būs nepieciešamas papildu oriģinālās pazīmes, kas norāda uz dārgu transportlīdzekli, lai būtu iespējams izveidot precīzāku modeli.
Stratifikācija
TableTorch pēc noklusējuma izmanto stratificētu vienmērīgu nejaušu izlases veidošanu loģistiskajām regresijām, lai izveidotu objektīvu modeli. Tomēr tas ne vienmēr var būt vēlams. Šāda modeļa veiktspēja, visticamāk, būs pielāgota sensitivitātes raksturlielumam nepietiekami pārstāvētajai klasei. 1 kolonnas is expensive gadījumā tiek piešķirts tikai 10% ierakstu.
Tāpēc, ja tiek izmantota stratificēta proporcionāla nejaušā izlases veidošana, regresija, visticamāk, būs vidēji precīzāka. Mūsu piemēram proporcionālās izlases veidošanas izmantošana radīs modeli ar AUC-ROC tikai 27%. Tomēr tam būs arī precizitāte klasei 1 98,4% pie sliekšņa 0,05 ar sensitivitāti klasei 1 62%. Šāds modelis var nebūt lielisks katras dārgās automašīnas identificēšanā, bet, kad tas norāda, ka transportlīdzeklis ir dārgs, iespējas ir augstas, ka tā patiešām ir.
Skatīt arī
Google, Google Izklājlapas, Google Workspace un YouTube ir Google LLC preču zīmes. Gaujasoft TableTorch nav saistīts ar Google un to neveicina Google.
Pasakiet mums!
Paldies, ka izmantojat vai apsverot izmantot TableTorch!
Vai šī lapa precīzi un atbilstoši apraksta attiecīgo funkciju? Vai tā patiešām darbojas tā, kā šeit izskaidrots, vai arī ir kāda problēma? Vai jums ir kādi ieteikumi, kā mēs varētu uzlaboties?
Lūdzu, paziņojiet mums, ja jums ir kādi jautājumi.
- E-pasts: ___________
- Facebook lapa
- Twitter profils