Logistische Regression
Die logistische Regression passt ein Modell an, das die Wahrscheinlichkeit vorhersagt, dass eine Zeile zu einer bestimmten Klasse gehört.
In einem Datensatz von Fabrikmaschinen lässt sich beispielsweise die Wahrscheinlichkeit eines Geräteausfalls innerhalb von 2 Wochen ohne dringende Wartung vorhersagen, sodass sich das Team auf die Geräte konzentrieren kann, die am dringendsten Aufmerksamkeit benötigen. Weitere Beispiele sind die Vorhersage von Kundenabwanderung, Mitarbeiterfluktuation oder dem Interesse eines Kunden an einem bestimmten Thema. Die Anwendungsmöglichkeiten sind nahezu grenzenlos.
- Erste Schritte mit TableTorch
- Identifizierung teurer Fahrzeuge
- Optimierung der logistischen Regression
- Stratifizierung
- Siehe auch
Die logistische Regression ist eine besondere Art der linearen Regression. Sie erfordert, dass die abhängige Variable (Zielvariable) entweder 1 oder 0 ist und angibt, ob ein Datensatz zur Klasse gehört oder nicht. Sie passt ein lineares Modell an, dessen Zielwert mit der logistischen Funktion transformiert wird.
Die logistische Funktion ist wie folgt definiert:
![]()
Während der Schätzung wird diese Formel mit folgenden Argumenten angewendet:
L = 1
k = 1
x0 = 0
wobei x das Ergebnis der Schätzung des linearen Modells ist. Damit liegen die Vorhersagen des logistischen Modells im Intervall (0; 1) und lassen sich als Wahrscheinlichkeiten interpretieren, dass die Zeile zur Klasse gehört.

TableTorch bietet für die Durchführung logistischer Regressionen denselben erweiterten Funktionsumfang wie für lineare Regressionen. Weitere Informationen zu verschiedenen Lern- und Sampling-Optionen finden Sie auf der Seite Feinabstimmung von Regressionen.
In den folgenden Abschnitten werden wir ein logistisches Modell anpassen, das vorhersagt, ob die Spalte selling_price des Fahrzeugdatensatzes 1.025.000 überschreitet, was dem 90. Perzentil dieser Spalte entspricht.
Erste Schritte mit TableTorch
- Installieren Sie TableTorch für Google Tabellen über den Google Workspace Marketplace. Weitere Informationen zur Ersteinrichtung.
- Klicken Sie auf das TableTorch-Symbol
 im rechten Seitenbereich von Google Tabellen.
im rechten Seitenbereich von Google Tabellen.
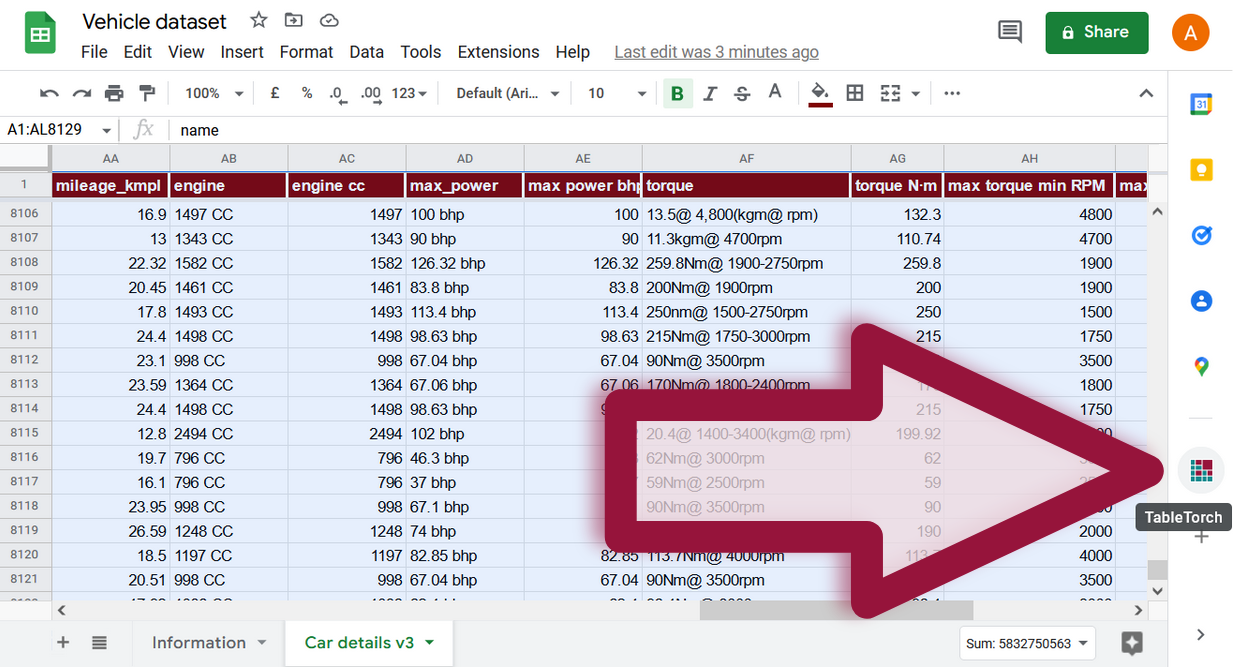
Identifizierung teurer Fahrzeuge
Fügen Sie die Spalte is expensive nach selling_price mit der Formel hinzu:
=IF(M2 > 1025000, 1, 0)
Wählen Sie den gesamten Bereich des Blattes aus und klicken Sie auf den Menüpunkt Logistic regression in TableTorch.
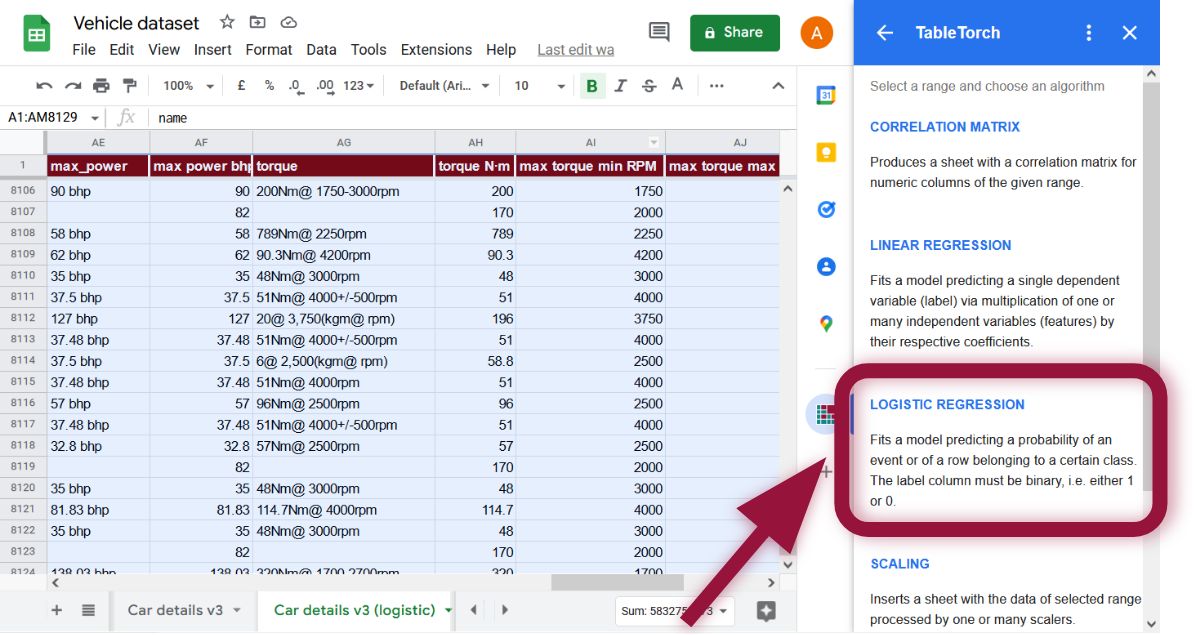
Setzen Sie die Spalte is expensive als Zielklasse. Deaktivieren Sie zusätzlich die Spalte selling_price in der Merkmalsliste, da unsere Zielklasse davon abhängt und sie daher nicht in der Regression verwendet werden sollte.
Klicken Sie auf Fit model, um die Regression durchzuführen. Kurz darauf erscheint die Regressionszusammenfassung, die etwa so aussehen sollte:
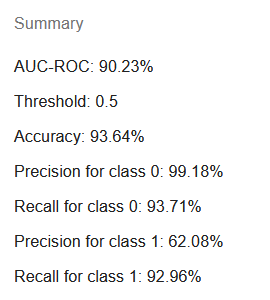
Beachten Sie, dass die angezeigten Kennzahlen sich von denen unterscheiden, die für lineare Regressionen erscheinen. Das ist auch richtig so, denn RMSE oder R² zu schätzen ergibt hier wenig Sinn — uns interessiert vielmehr die Genauigkeit der Klassenzuordnung als die exakte Abweichung zwischen der Vorhersage und dem Wert 1 oder 0 der Zielklasse.
AUC-ROC (Area Under Curve — Receiver Operating Characteristic) ist eine häufig verwendete Kennzahl zur Schätzung der Wahrscheinlichkeit, dass die Vorhersage des Modells korrekt ist.
Threshold (Schwellenwert) ist standardmäßig immer 0,5 und wird in der Zusammenfassung angezeigt, da die folgenden Kennzahlen wie Genauigkeit, Präzision und Sensitivität davon abhängen. Binäre Klassifikatoren, die auf logistischen Modellen basieren, weisen einer Zeile die Klasse zu, wenn die Vorhersage größer oder gleich dem Schwellenwert ist.
In einem späteren Abschnitt sehen wir uns das ausführliche Zusammenfassungsblatt der logistischen Regression genauer an, das uns helfen kann, je nach unseren Prioritäten einen anderen Schwellenwert zu wählen.
Accuracy (Genauigkeit) gibt den Anteil der Zeilen an, für die das Modell die richtige Antwort geliefert hat.
Precision for class 0 und precision for class 1 (Präzision für Klasse 0/1) geben den Anteil der Zeilen an, die korrekt als zu einer bestimmten Klasse gehörend vorhergesagt wurden. Beträgt zum Beispiel die Präzision für Klasse 1 62 %, heißt das, dass 38 % der Zeilen, die als zur Klasse 1 gehörend vorhergesagt wurden, tatsächlich nicht dazu gehörten — was auf eine erhebliche Rate von Falsch-Positiven hindeutet.
Recall for class 0 und recall for class 1 (Sensitivität für Klasse 0/1) geben den Anteil der Zeilen an, die tatsächlich zu einer bestimmten Klasse gehören und vom Modell auch korrekt dieser Klasse zugeordnet wurden. Beträgt zum Beispiel die Sensitivität für Klasse 1 93 %, dann wurde für 7 % der Zeilen, die tatsächlich zur Klasse 1 gehören, eine falsche Vorhersage abgegeben.
Klicken Sie auf die Schaltfläche Insert prediction column. Der Wert in jeder Zeile der erzeugten Spalte gibt die vom Modell geschätzte Wahrscheinlichkeit an, dass das jeweilige Fahrzeug einen selling_price über 1.025.000 hat.
Mit dieser Wahrscheinlichkeit ist es nun möglich, eine binäre Klassifikatorspalte einzufügen. Der einzige wichtige Parameter, der noch bestimmt werden muss, ist der Schwellenwert, ab dem einer Zeile die Klasse is expensive zugewiesen werden soll:
=IF(AN2 >= 0.5, 1, 0)
Die Zahl 0.5 in der obigen Formel ist der besagte Schwellenwert. 0,5 liefert für das Modell oft die ausgewogenste Leistung in Bezug auf Sensitivität, Präzision und Genauigkeit. Je nach unseren Zielen kann jedoch ein anderer Wert besser geeignet sein.
Klicken Sie auf die Schaltfläche Add summary sheet und überprüfen Sie die Details der Regression.

Zusätzlich zu Intercept und Koeffizienten, die in der Zusammenfassung jeder linearen Regression vorhanden sind, enthält das Zusammenfassungsblatt für die logistische Regression die Tabelle der Kennzahlen Präzision, Sensitivität und Genauigkeit bei verschiedenen Schwellenwert-Niveaus.
Möchten wir beispielsweise ein präziseres Modell, das Zeilen seltener fälschlich die Klasse 1 zuweist, kommt der Schwellenwert 0,87 statt 0,5 in Frage: An diesem Punkt erreicht die Präzision 90 % statt nur 62 % beim Schwellenwert 0,5. Wir sehen jedoch auch, dass beim Schwellenwert 0,87 die Sensitivität auf knapp 80 % sinkt — deutlich weniger als die fast 93 %, die beim Schwellenwert 0,5 erreichbar sind.
Umgekehrt kann die Wahl eines niedrigeren Schwellenwerts, z. B. 0,13, die Sensitivität des Klassifikators erheblich verbessern und fast 99 % erreichen — allerdings auf Kosten einer Reduzierung der Präzision auf etwa 40 %.
Es gibt jedoch einen Weg, das gewünschte Niveau der Präzision oder Sensitivität zu erreichen, ohne die andere Kennzahl zu opfern: ein besseres Modell zu erstellen.
Optimierung der logistischen Regression
Sämtliche Optionen, die auf der Seite Feinabstimmung linearer Regressionen besprochen werden, lassen sich auch auf logistische Regressionen anwenden, da der zugrunde liegende Prozess derselbe ist.
Versuchen wir die folgenden Optimierungsschritte:
- Wenden Sie die auf der Seite Feinabstimmung von Regressionen beschriebenen Techniken zur Merkmalskonstruktion und Spaltenausschluss an.
- Aktivieren Sie 3-Fold Cross-Validation.
-
Fügen Sie weitere herstelleridentifizierende Spalten auf die gleiche Weise hinzu, wie wir es bei der Vorbereitung des Fahrzeugdatensatzes getan haben.
-
Volvo
=IF(ISNUMBER(FIND("Volvo", A2)), 1, 0) - BMW
=IF(ISNUMBER(FIND("BMW", A2)), 1, 0) - Audi
=IF(ISNUMBER(FIND("Audi", A2)), 1, 0) - Mercedes-Benz
=IF(ISNUMBER(FIND("Mercedes-Benz", A2)), 1, 0) - Lexus
=IF(ISNUMBER(FIND("Lexus", A2)), 1, 0) - Jaguar
=IF(ISNUMBER(FIND("Jaguar", A2)), 1, 0) - Jeep
=IF(ISNUMBER(FIND("Jeep", A2)), 1, 0) - Land Rover
=IF(ISNUMBER(FIND("Land Rover", A2)), 1, 0) - Volkswagen
=IF(ISNUMBER(FIND("Volkswagen", A2)), 1, 0)
-
-
Fügen Sie weitere abgeleitete Merkmale hinzu:
- perceived wear
=Z2 / (Y2 / MAX($Y$2:$Y$8129))
wobei Z die Spalte km_driven und Y die Spalte average price of year ist.
- depreciated torque N·m
=AU2 * Y2 / MAX($Y$2:$Y$8129)
wobei AU die Spalte torque N·m und Y die Spalte average price of year ist.
- perceived wear
- Wählen Sie den gesamten Bereich aus und öffnen Sie das Tool Logistic regression in TableTorch.
- Verwenden Sie stratifizierte gleichmäßige Zufallsstichproben mit year stratum als Stratumsspalte.
- Deaktivieren Sie die Spalten year, selling_price, is expensive, km_driven, petrol, max power bhp, engine cc, torque N·m, max torque min RPM in der Merkmalsliste.
- Klicken Sie auf Fit model.
Das erzeugte Modell hat eine Zusammenfassung wie diese:
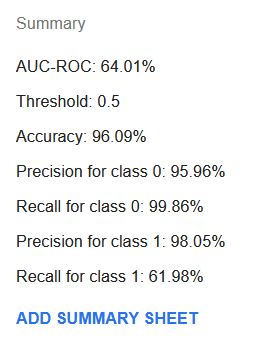
Obwohl AUC-ROC mit 64 % recht niedrig geworden ist, haben sich Genauigkeit, Sensitivität für Klasse 0 und Präzision für Klasse 1 stark verbessert. Die Sensitivität für Klasse 1 ist deutlich auf nur 62 % gefallen. Werfen wir jedoch einen Blick auf das Zusammenfassungsblatt, lässt sich ein Schwellenwert finden, z. B. 0,11, bei dem die Sensitivität bei 83 %, die Präzision bei 89 % und die Genauigkeit bei 97 % liegt.
Das neue Modell ist wahrscheinlich besser als das mit den Standardeinstellungen erzielte, sieht aber immer noch nicht nach einer signifikanten Verbesserung aus. Vielleicht benötigt der Datensatz weitere Rohmerkmale, die auf ein teures Fahrzeug hindeuten, damit sich ein präziseres Modell anpassen lässt.
Stratifizierung
TableTorch verwendet standardmäßig stratifizierte gleichmäßige Zufallsstichproben für logistische Regressionen, um ein unverzerrtes Modell zu erzeugen. Das ist jedoch nicht immer wünschenswert, da die Leistung eines solchen Modells wahrscheinlich stark auf die Sensitivitäts-Kennzahl für die unterrepräsentierte Klasse zugeschnitten wäre (im Fall der Spalte is expensive ist die Klasse 1 nur etwa 10 % der Datensätze zugeordnet).
Werden hingegen stratifizierte proportionale Zufallsstichproben verwendet, ist die Regression im Durchschnitt wahrscheinlich präziser. In unserem Beispiel führt die Verwendung proportionaler Stichproben zu einem Modell mit einem AUC-ROC von nur 27 %, das jedoch eine Präzision für Klasse 1 von 98,4 % bei einem Schwellenwert von 0,05 mit einer Sensitivität für Klasse 1 von 62 % aufweist. Ein solches Modell ist nicht unbedingt geeignet, jedes teure Fahrzeug zu erkennen — wenn es jedoch anzeigt, dass ein Fahrzeug teuer ist, trifft das mit hoher Wahrscheinlichkeit auch zu.
Siehe auch
- Lineare Regression
- Feinabstimmung von Regressionen
- Artikel zur logistischen Regression auf Wikipedia
Google, Google Tabellen, Google Workspace und YouTube sind Marken von Google LLC. Gaujasoft TableTorch ist nicht mit Google verbunden und wird nicht von Google unterstützt.
Ihr Feedback ist uns wichtig!
Vielen Dank, dass Sie TableTorch verwenden oder in Betracht ziehen!
Beschreibt diese Seite die Funktion korrekt und verständlich? Funktioniert sie tatsächlich so, wie hier beschrieben, oder gibt es ein Problem? Haben Sie Verbesserungsvorschläge?
Bei Fragen können Sie sich jederzeit gerne an uns wenden.
- E-Mail: ___________
- Facebook-Seite
- Twitter-Profil