Regresiju uzlabošana
Lineārā regresija, kas veikta kā piemērs šajā lapā, demonstrēja, ka pat ar noklusējuma iestatījumiem TableTorch var izveidot modeli ar pieņemamu veiktspēju. Tomēr vai šī veiktspēja varētu būt vēl labāka ar atšķirīgu konfigurāciju? Noskaidrosim.
- Mācīšanās opcijas
- Izlases opcijas
- Pazīmju inženierija
- gada strata
- Inflācijas un nolietojuma ņemšana vērā
- depreciated max power bhp (AG)
- Modeļa apmācīšana ar jaunām pazīmēm
- Datu noplūde
- Secinājums
Turpināsim izmantot transportlīdzekļu datu kopu un mēģināsim prognozēt kolonnas selling_price vērtību.
TableTorch nodrošina divas regresijas opciju sadaļas: apmācības opcijas, kas ietekmē regresijas algoritmu, un izlases opcijas, kas konfigurē sākotnējās datu kopas izlases procesu, sadalot to atsevišķās treniņu/testa kopās, kā arī pēc izvēles izmantojot K-kāršīgo šķērsvalidāciju, kas veic vairākas regresijas un automātiski izvēlas labāko modeli.
Sāksim ar pieejamo apmācības opciju izpēti.
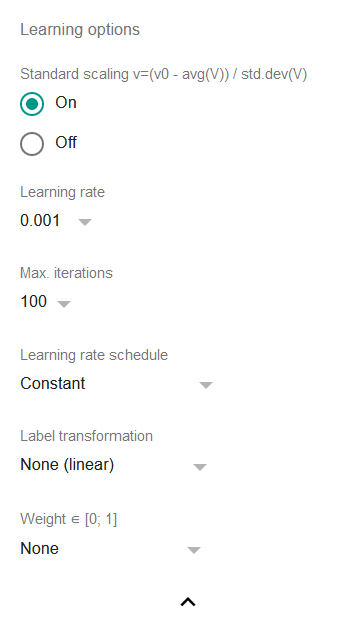
Mācīšanās opcijas
-
Std. mērogošana: ja tas ir ieslēgts, tad visas pazīmes un rezultatīvā pazīme tiks standarta mērogotas pirms modeļa apmācīšanas, t.i., regresija darbosies ar vērtībām, kas apstrādātas ar formulu
v=(v0 - average(V)) / std.dev(V)kur
v0ir sākotnējā vērtība unVir visu pieejamo vērtību kopa.Standarta mērogošana ir plaši atzīta prakse lineārām regresijām, un būtībā ir jēga to izslēgt tikai tad, ja sākotnējie dati jau ir mērogoti.
-
Mācīšanās ātrums: ļoti svarīgs parametrs jebkuram gradientu nolaišanās algoritmam, tas nosaka tempu, kādā algoritms maina koeficientus, cenšoties sasniegt konverģenci. Augstākas vērtības var padarīt regresiju ātrāku, bet vairāk pakļautu augšup un lejup lēkāšanai pa noteiktiem līmeņiem. Zemākas vērtības palēnina procesu un var pat novest pie situācijas, kad iterāciju skaits konverģences sasniegšanai būtu nepieņemami liels. Kā vispārīgs noteikums, vai nu 0,01, vai 0,001 darbosies labi vairumā situāciju, bet TableTorch nodrošina arī citas opcijas.
-
Maks. iterācijas: maksimālais iterāciju (epohu) skaits, ko veikt regresijas laikā. Parasti nav jēgas mainīt šo parametru, jo noklusējuma 100 ir diezgan liels skaits, un regresija tik un tā apstāsies, kad pēdējo dažu iterāciju uzlabojums būs mazāks par 1E-6 (0,000001) no relatīvās kļūdas.
-
Mācību ātruma grafiks: ja nav konstants, samazina mācīšanās ātrumu atbilstoši pēc katras epohas. Tas varētu ļaut regresijai uztvert ļoti smalku datu signālu.
-
Rezultatīvās pazīmes pārveidošana: ja nelineārs, pārveido rezultatīvo pazīmi pirms no tās mācīšanās. Tas ļauj veikt lineārās regresijas uz rezultatīvām pazīmēm, kurām nav lineāras atkarības no neatkarīgajiem mainīgajiem, neievadot papildu kolonnas.
a) Eksponenciālā variants pieņem, ka rezultatīvā pazīme ir eksponenciāli atkarīga no atlasītajām pazīmēm un mēģinās prognozēt e pakāpi, nevis lineāru vērtību.
b) Loģistiskā variants pieņem, ka rezultatīvā pazīme ir diapazonā [0; 1] un apzīmē rindas bināru klasifikāciju, kas pieder noteiktai klasei vai notikumam. Ieteicams izmantot TableTorch loģistiskās regresijas rīku, nevis šo opciju, jo tas arī izveidoš noderīgāku kopsavilkumu.
-
Svars: ja norādīts, tad regresija izmanto svērtās mazāko kvadrātu metodi, nevis parastās mazākās kvadrātas. Praksē kolonna, kas norādīta kā svars, ietekmē mācīšanās ātrumu katrai konkrētai rindai un var tikt izmantota, lai izslēgtu vai samazinātu izlecošo rindu ietekmi.
Iestatīsim Rezultatīvās pazīmes pārveidošana uz Eksponenciālā un veiksim regresiju vēlreiz.

Pārsteidzoši, gan R², gan MAE rādītāji ir uzlabojušies dramatiski, R² sasniedzot 0,75 un MAE gandrīz uz pusi samazinoties līdz 136 000.
Tas varētu liecināt, ka patiešām pastāv eksponenciāla attiecība starp selling_price un transportlīdzekļa pazīmēm. Tomēr transportlīdzekļu datu kopā trūkst tādu pazīmju kā ekonomiskā inflācija vai uzkrātā transportlīdzekļa nolietojuma likme, tāpēc varētu būt pāragri izdarīt secinājumu par atkarības raksturu starp transportlīdzekļa pazīmēm un selling_price.
Atgriezīsimies uz mirkli un pārslēgsim Rezultatīvās pazīmes pārveidošana atpakaļ uz Nav (lineāra), lai izpētītu izlases opcijas.
Izlases opcijas
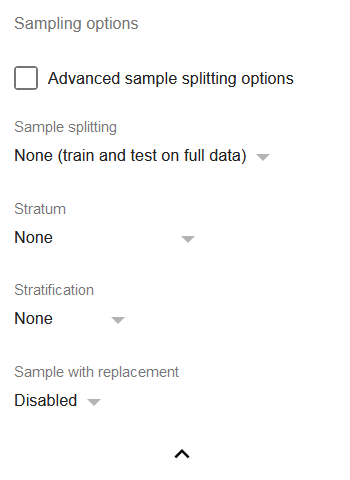
- Uzlabotas izlašu sadalīšanas opcijas: atzīmējiet, ja vēlaties precīzāk norādīt treniņa daļu treniņu/testu sadalījumam vai k-kārtīgai šķērsvalidācijai.
-
Izlases sadalīšana: visbiežāk izmantoto datu kopas sadalīšanas metožu kopa regresijām:
a) Apmācība-validācija 50/50: sadala datu kopu tā, ka tikai 50% datu tiek izmantoti treniņam.
b) Apmācība-validācija 80/20: tas pats kā (a), bet ar lielāku datu daļu, kas tiek izmantota treniņam.
c) 3 reižu savstarpēja validācija: sadala datu kopu trīs vienāda lieluma izlasēs A, B un C, un pēc tam veic trīs dažādas regresijas: pirmā trenēta uz izlasēm (A, B) un validēta uz izlases C, otrā trenēta uz izlasēm (B, C) un validēta uz izlases A, trešā trenēta uz izlasēm (A, C) un validēta uz izlases B, pēc tam izvēlas modeli ar augstāko R².
d) 5 reižu savstarpēja validācija un 10 reižu savstarpēja validācija: vispārīgi tas pats kā (c), bet ar lielāku kāršu skaitu, t.i., veicamo regresiju skaitu.
-
Stratum: ļauj izvēlēties kolonnu, kas identificē stratu, kurai rinda pieder.
-
Stratifikācija: ja ir atlasīta viena no sadalīšanas opcijām, ir iespējams atlasīt vienu no stratifikācijas stratēģijām:
a) Nav: rindas nonāk katrā sadalījumā uz nejaušības pamata.
b) Proporcionāla: katra strata ir pārstāvēta katrā sadalījumā tādā pašā proporcijā, kāda tai bija visā datu kopā.
c) Vienota: visām stratām ir vienāds rindu skaits katrā sadalījumā. Ja izlase ar nomaiņu ir atspējota, rindu skaitu nosaka rindu skaits mazākajā stratā. Pretējā gadījumā rindu skaitu nosaka rindu skaits lielākajā stratā. Tādējādi parasti ir jēga iespējot nomaiņu stratificētās vienmērīgās izlases gadījumā.
- Izlase ar nomaiņu: ja iespējots, katra sadalījuma izlase tiks veikta ar nomaiņu, t.i., būs varbūtība, ka tā pati rinda parādīsies sadalījumā divas reizes. Tas ir īpaši noderīgi nelīdzsvarotām datu kopām, kurās konkrēta strata ir nepietiekami pārstāvēta. Ar nomaiņu ir iespējams izmantot nejaušu vienmērīgu stratifikāciju un izvairīties no signāla zuduma, kas saistīts ar mazu rindu skaitu.
Veiks selling_price regresiju vēlreiz ar izlases sadalīšanas opciju iestatītu uz 3 reižu savstarpēja validācija.

Interesanti, R² ir ievērojami uzlabojies, sasniedzot 0,83, savukārt MAE ir palielinājies līdz aptuveni 283 000. Tas var šķist mulsinoši, jo tas norāda, ka modelis tagad, iespējams, uztver dispersiju labāk, lai gan vidējā absolūtā kļūda ir palielinājusies.
Tomēr jāatceras, ka šie rezultāti tika sasniegti, trenējoties tikai uz divām trešdaļām datu. Tas nozīmē, ka šis modelis ir parādījis noturību pret datiem, ko tas neredzēja apmācības procesa laikā. Tas ir galvenais iemesls, kāpēc bieži izmantota prakse ir veikt K-kāršīgo šķērsvalidāciju praktiski jebkurā gadījumā, jo tā aizsargā modeli pret pārmērīgu apmācību.
Pazīmju inženierija
Transportlīdzekļu datu kopas sagatavošanas procesā mēs jau esam modificējuši datu kopu, lai pārvērstu teksta informāciju skaitliskos datos. Tomēr mēs neieviesām nekādas palīgpazīmes, kas varētu palīdzēt regresijai.
Turklāt mēs nepievērsām daudz uzmanības datu kopas korelācijas matricai, lai gan tā varētu būt būtiska, lai izslēgtu ļoti korelētus mainīgos no regresijas.
Korelācijas matricas rīks izveido šādu matricu datu kopai:

Koeficienti parāda, ka dažas kolonnas var izslēgt no selling_price kolonnas regresijas:
- max torque max RPM tās augstās korelācijas dēļ ar max torque min RPM un niecīgās korelācijas ar selling price.
- petrol tās ļoti nozīmīgās korelācijas ar diesel dēļ.
- engine cc tās korelācijas ar max power bhp dēļ, kur pēdējam ir augstāka korelācija ar selling_price.
Atcelēsim kolonnu max torque max RPM, petrol, and engine cc atlasi pirms regresijas veikšanas.
Iespējojiet 3-kāršīgo šķērsvalidāciju un noklikšķiniet Apmāciet modeli, lai veiktu regresiju.

Regresijas veiktspēja ne uzlabojās, ne pasliktinājās, kas ir labs zīme: jo mazāk pazīmju, lai izveidotu tādas pašas kvalitātes modeli, jo labāk.
Tagad mēģināsim hipotizēt, kādas papildu pazīmes varētu atvasināt no mainīgajiem, kas jau ir klāt, veidā, kas palīdzētu regresijai izskaidrot dispersiju rezultatīvajā pazīmē.
gada strata
Ja apskatām rindu skaitu vienam year, izrādās, ka ir daudz gadu ar tikai dažiem ierakstiem.
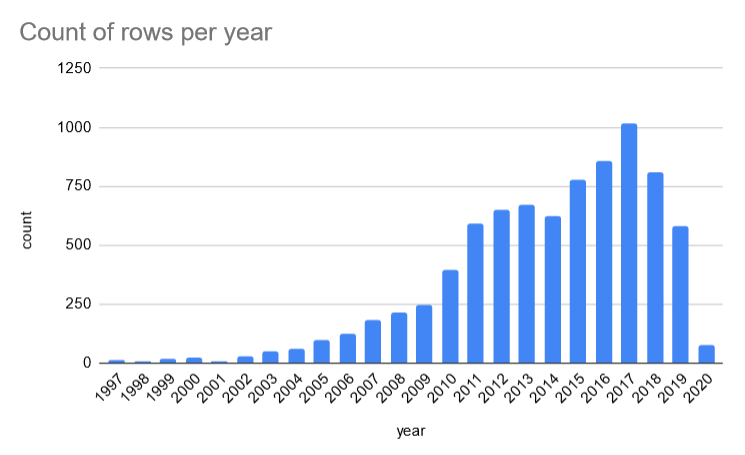
Varētu būt jēga grupēt ierakstus tikai dažās kohortās vai stratās:
- 1-3 gadi (
year >= 2018); - 4-8 gadi (
AND(year >= 2013, year < 2018)); - 9-15 gadi (
AND(year >= 2006, year < 2013); - vairāk nekā 15 gadi veci (
year < 2006).
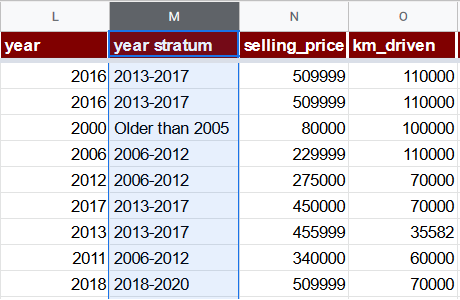
Ievietosim kolonnu year stratum tieši pēc year (L) kolonnas ar formulu:
=IFS(L2 >= 2018, "2018-2020", L2 >= 2013, "2013-2017", L2 >= 2006, "2006-2012", TRUE, "Older than 2005")
Ievērojiet, ka šai kolonnai ir teksta vērtība, nevis skaitliska. Tas ir pareizi, tā netiks tieši izmantota regresijā, bet gan palīdzēs atvasināt citas pazīmes un arī tiks izmantota stratificētā vienmērīgā nejaušā izlasē.
Inflācijas un nolietojuma ņemšana vērā
Ņemot vērā, ka transportlīdzekļiem ir tendence pasliktināt savu stāvokli ar vecumu un ka jaunajiem modeļiem tiek pievienotas arvien brīnišķīgākas jaunas funkcijas, ir saprātīgi ieviest sava veida inflāciju + nolietojumu pazīmi, lai novērtētu šo parādību vidējo ietekmi uz konkrētu rindu.
Viena iespēja to izdarīt būtu ieviest papildu datus datu kopā, kas pārstāv uzkrāto transportlīdzekļa cenu inflāciju noteiktā gadā, kā arī nolietojuma likmi konkrētam modelim. Tomēr dažkārt papildu dati var nebūt viegli pieejami vai to iegūšana varētu radīt papildu izmaksas.
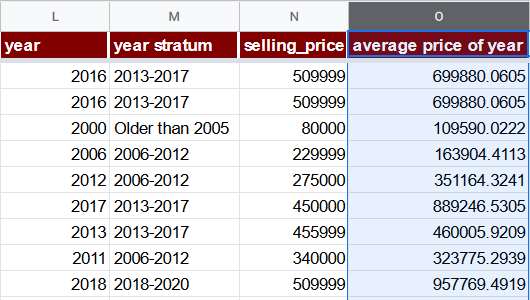
Tādējādi izmantosim citu opciju: average price of year (O) kolonnu. Tās formula vienkārši apkops vidējo cenu visiem transportlīdzekļiem, kas ražoti noteiktā gadā. Tā kā ir mazāk par 100 ierakstiem gadā gadiem, kas ir mazāki par 2006, tiem izmantosim “Older than 2005” stratas vidējo cenu. Ņemiet vērā, ka šādas pazīmes ieviešana ir datu noplūdes forma, ko mēs apspriedīsim vēlāk šajā lapā.
=IF(L2 <= 2005, AVERAGEIF($M$2:$M$8129, "Older than 2005", $N$2:$N$8129), AVERAGEIF($L$2:$L$8129, L2, $N$2:$N$8129))
depreciated max power bhp (AG)
Visās selling_price regresijās, kas līdz šim veiktas, visnozīmīgākais koeficients ir bijis nemainīgi piešķirts max power bhp pazīmei.
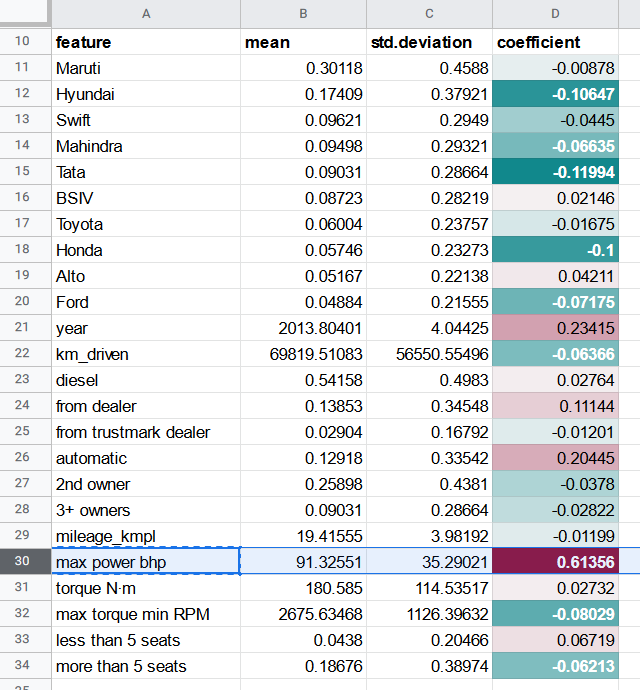
Tomēr, tā kā automašīnas veiktspēja degradējas ar laiku, 100 bhp specifikācija automašīnai, kas ražota 2000. gadā, var nenozīmēt jaudu, kas identiska automašīnai, kas ražota 2020. gadā ar to pašu bhp rādītāju.
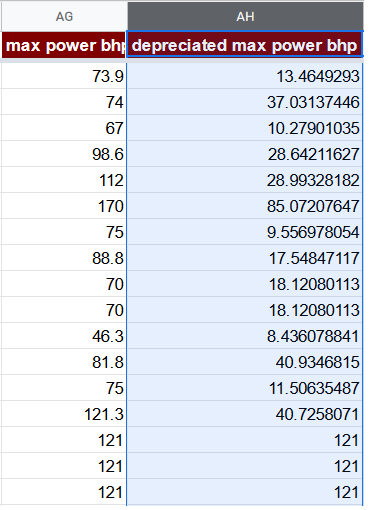
Iespējamais veids, kā koriģēt max power bhp pazīmi mūsu gadījumā, ir to reizināt ar average price of year un pēc tam dalīt ar maksimālo average price of year. Šīs pazīmes nozīme būtu max power bhp uztvertā vērtība automašīnai ar konkrētu vecumu.
=AG2 * O2 / MAX($O$2:$O$8129)
Modeļa apmācīšana ar jaunām pazīmēm
Korelācijas matrica attiecībā uz selling_price, year un atvasinātām pazīmēm izskatās šādi:
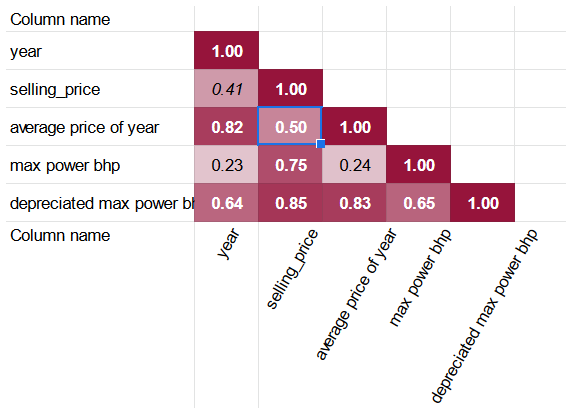
Labā ziņa ir, ka depreciated max power bhp kolonnai ir augstāks korelācijas koeficients ar selling_price nekā neskarotajai max power bhp. Turklāt average price of year arī ir korelēts ar selling_price nozīmīgāk nekā vienkāršāka year kolonna.
Pievienosim šīs jaunās pazīmes regresijai, vienlaikus noņemot kolonnas year un max power bhp no tās. Kolonnām max torque max RPM, petrol, un engine cc arī jābūt neatzīmētām pazīmju sarakstā, kā tika apspriests iepriekš. Turklāt 3 reižu savstarpēja validācija iestatījumam arī jābūt iespējotam.
Tagad, kad ir arī year stratum kolonna, tā jāiestata kā stratas kolonna, un stratifikācija jāiestata uz vienota. Tas nodrošinās, ka katra kārta satur tieši vienādu rindu skaitu no katras stratas, samazinot modeļa neobjektivitāti pret jaunākiem vai vecākiem transportlīdzekļiem.
Visa regresijas konfigurācija ir parādīta zemāk.
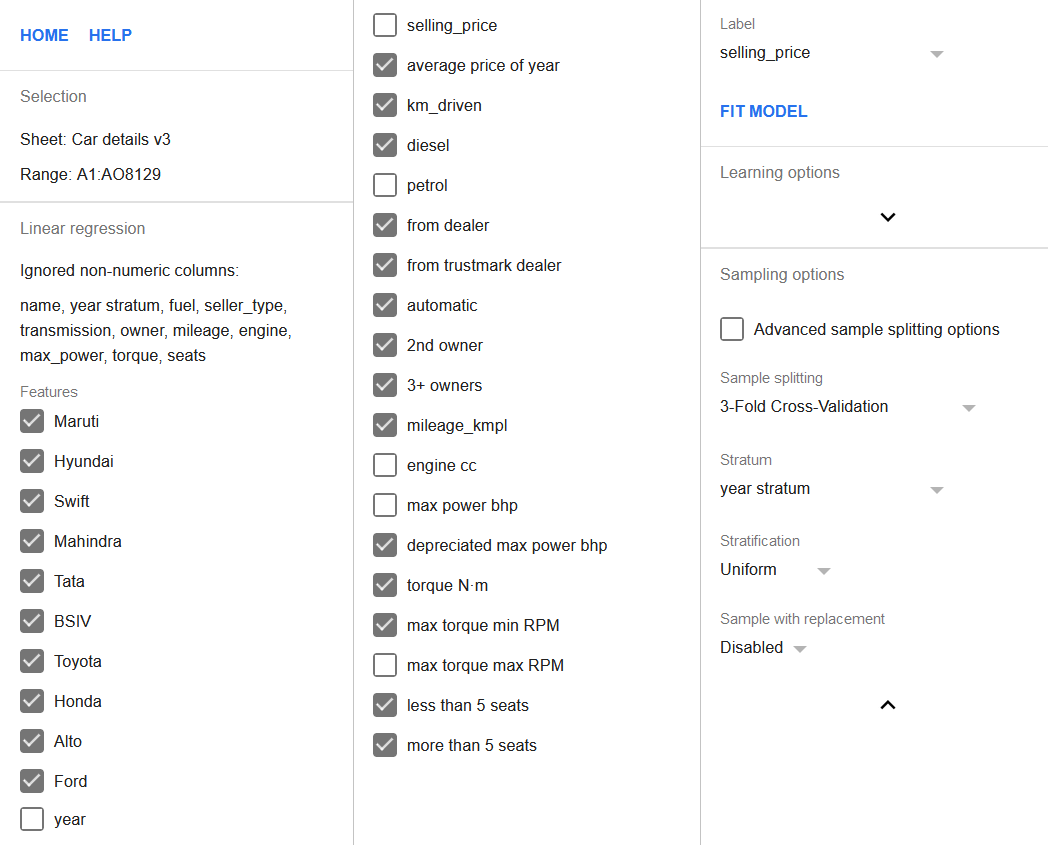
Noklikšķiniet uz pogas Apmāciet modeli, lai veiktu regresiju.

Fascinējoši, R² gandrīz kļuva tik labs, cik tas varētu būt, ar 0,99. Gan RMSE, gan MAE kļūst ievērojami zemāki nekā regresijā ar noklusējuma iestatījumiem un bez jebkādām atvasinātām pazīmēm.
Turklāt, ja ievietojam prognozes kolonnu un relative error
kolonnu =ABS((AP2 - N2) / N2) (kur N ir selling_price
un AP2 ir prediction) un pēc tam kārtojam pēc relative error,
varam redzēt, ka 19% rindu prognozes kļūda ir 10% vai mazāka
no novērotās selling_price, un mediānas relatīvā kļūda ir aptuveni
28,8%.
Datu noplūde
Jāatzīmē, ka pazīmes atvasināšana no atkarīgā mainīgā, kā mēs izdarījām ar average price of year kolonnu, ievieš datu noplūdi. Tā ir situācija, kad rezultatīvā pazīme tiek prognozēta, pamatojoties uz datiem, kas satur pati sevi. Tas var sarežģīt vai pat padarīt neiespējamu modeļa izmantošanu uz jauniem datiem.
Average price of year, piemēram, varētu pārvietot uz atsevišķu
diapazonu, un jauniem datiem mēs varētu izmantot LOOKUP funkciju, lai iegūtu
pazīmes vērtību, jo AVERAGEIF nebūs praktisks, jo nav
novērotu vērtību selling_price. Tomēr, ja sastopamies ar
rindu, kurai ir year vērtība, kas netika novērota
modeļa treniņa laikā, būtu neiespējami atrast atbilstošu
average price of year, un būtu jāizmanto labākais pieņēmums,
piemēram, atrodot vērtību tuvākajam gadam.
Tādējādi uzlabotie uzlabotā modeļa rādītāji jāvērtē piesardzīgi: tas var nedarboties tik labi prognozes laikā, ja dažas no atvasinātajām pazīmēm nevar uzticami iegūt.
Secinājums
Mēs mēģinājām demonstrēt, ka opcijas, ko TableTorch nodrošina regresijas procesa uzlabošanai kopā ar nedaudz pazīmju inženierijas, var izveidot noturīgāku un uzticamāku modeli nekā tikai noklusējuma iestatījumu izmantošana. Nav robežu pilnveidei, un ir vairāk ko darīt ar transportlīdzekļu datu kopas modelēšanu.
Viens veids, kā uzlabot modeli, faktiski varētu būt uzdot tam citu jautājumu. Piemēram, tā vietā, lai mēģinātu prognozēt precīzu selling_price vērtību, mēs varētu mēģināt prognozēt, vai tas pārdotos par cenu, kas augstāka par noteiktu slieksni vai nē. TableTorch nodrošina piemērotu rīku, lai apmācītu modeli, kas specializējas šajos jautājumu veidos, loģistisko regresiju.
Skatīt arī Vikipēdijā (angļu valodā):
Google, Google Izklājlapas, Google Workspace un YouTube ir Google LLC preču zīmes. Gaujasoft TableTorch nav saistīts ar Google un to neveicina Google.
Pasakiet mums!
Paldies, ka izmantojat vai apsverot izmantot TableTorch!
Vai šī lapa precīzi un atbilstoši apraksta attiecīgo funkciju? Vai tā patiešām darbojas tā, kā šeit izskaidrots, vai arī ir kāda problēma? Vai jums ir kādi ieteikumi, kā mēs varētu uzlaboties?
Lūdzu, paziņojiet mums, ja jums ir kādi jautājumi.
- E-pasts: ___________
- Facebook lapa
- Twitter profils