Логистическая регрессия
Логистическая регрессия строит модель, предсказывающую вероятность принадлежности строки к определённому классу.
Например, в наборе данных о заводском оборудовании можно предсказать вероятность отказа оборудования в течение 2 недель без срочного обслуживания, помогая команде сосредоточиться на оборудовании, требующем наибольшего внимания. Другие примеры включают прогнозирование оттока клиентов, текучести кадров, интереса клиента к определённой теме. Возможности безграничны.
- Запуск TableTorch
- Определение дорогих автомобилей
- Настройка логистической регрессии
- Стратификация
- Смотрите также
Логистическая регрессия — это особый вид линейной регрессии. Она требует, чтобы зависимая переменная (метка) была либо 1, либо 0, обозначая, принадлежит ли запись к классу или нет, и строит линейную модель с меткой, преобразованной логистической функцией.
Логистическая функция определяется следующим образом:
![]()
При оценке эта формула применяется с аргументами
L = 1
k = 1
x0 = 0
где x — результат оценки линейной модели. Таким образом, прогнозы логистической модели принадлежат множеству (0; 1) и могут интерпретироваться как вероятности принадлежности строки к классу.

TableTorch предоставляет тот же расширенный набор функций для логистических регрессий, что и для линейных регрессий. Для получения дополнительной информации о различных параметрах обучения и выборки см. страницу тонкая настройка регрессий.
В следующих разделах мы построим логистическую модель, предсказывающую, превышает ли столбец selling_price из набора данных об автомобилях значение 1 025 000, что является 90-м процентилем этого столбца.
Запуск TableTorch
- Установите TableTorch для Google Таблиц через Google Workspace Marketplace. Подробнее о начальной настройке.
- Нажмите на иконку
 TableTorch
на правой боковой панели Google Таблиц.
TableTorch
на правой боковой панели Google Таблиц.
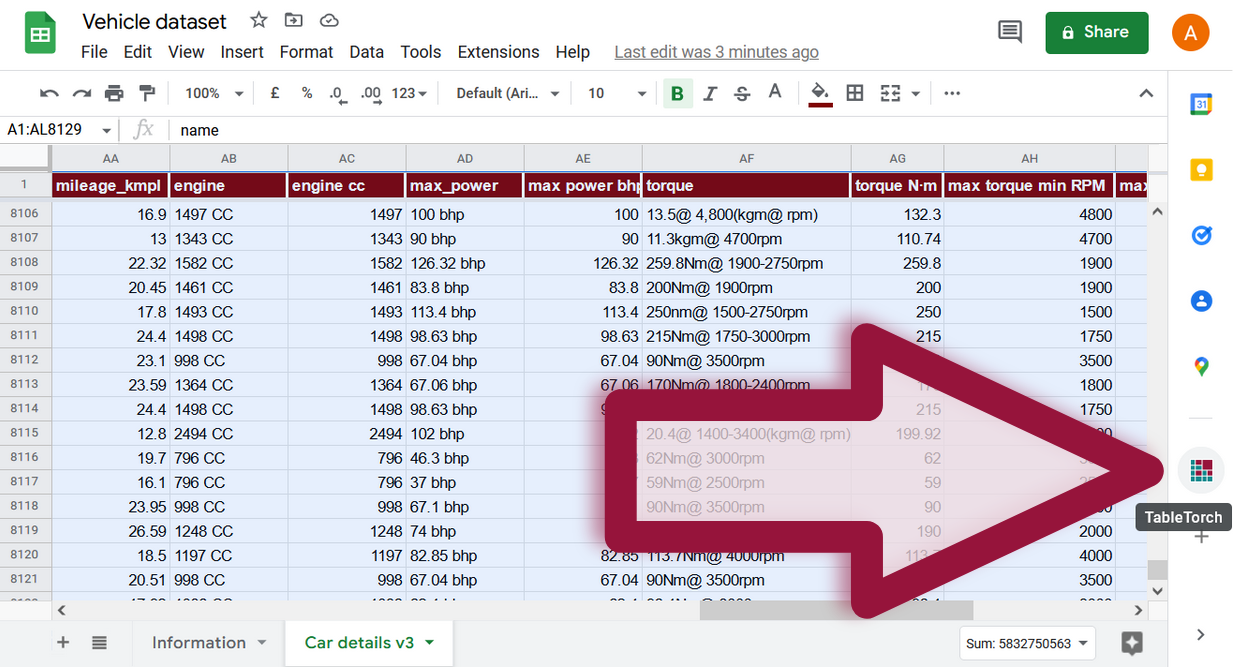
Определение дорогих автомобилей
Добавьте столбец is expensive после selling_price с формулой
=IF(M2 > 1025000, 1, 0)
Выберите весь диапазон листа и нажмите пункт меню Логистическая регрессия в TableTorch.
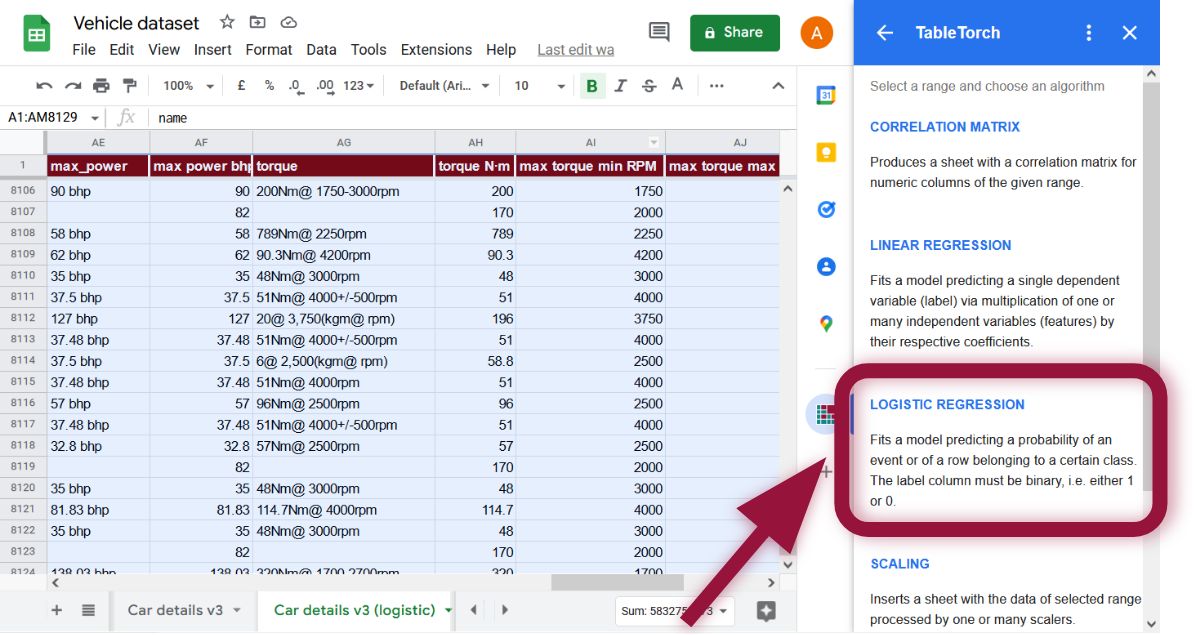
Установите столбец is expensive в качестве метки. Дополнительно снимите отметку со столбца selling_price в списке признаков, поскольку наша метка зависит от него, и он не должен использоваться в регрессии.
Нажмите Обучить модель для выполнения регрессии. Сводка регрессии появится через некоторое время и будет выглядеть примерно так:
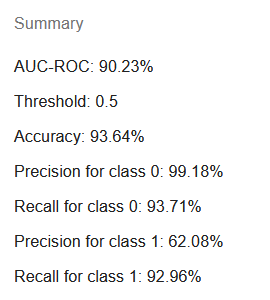
Обратите внимание, что показанные характеристики отличаются от тех, которые появляются для линейных регрессий. Это правильно — не имеет особого смысла оценивать RMSE или R², потому что нас больше интересует точность определения класса, а не точный остаток между прогнозом и 1 или 0 метки.
AUC-ROC (area under curve — receiver operating characteristic, площадь под ROC-кривой) — популярная метрика, оценивающая вероятность того, что прогноз модели окажется правильным.
Порог всегда по умолчанию равен 0,5 и присутствует в сводке, поскольку следующие метрики — доля верных, точность и чувствительность — зависят от него. Бинарные классификаторы на основе логистических моделей присваивают класс строкам с прогнозом, большим или равным порогу.
В следующем разделе этого документа мы рассмотрим подробный сводный лист логистической регрессии, который может помочь выбрать другой порог в зависимости от наших приоритетов.
Доля верных представляет долю строк, для которых модель успешно дала правильный ответ.
Точность для класса 0 и точность для класса 1 показывают, какая доля строк, отнесённых моделью к этому классу, действительно ему принадлежит. Например, если точность для класса 1 равна 62%, это означает, что 38% строк, предсказанных как принадлежащие классу 1, на самом деле к нему не относятся — заметная доля ложноположительных результатов.
Чувствительность для класса 0 и чувствительность для класса 1 означают долю строк, наблюдаемых как принадлежащие к определённому классу и также предсказанных моделью как принадлежащие к этому классу. Например, если чувствительность для класса 1 равна 93%, то 7% строк, наблюдаемых как принадлежащие к классу 1, получили неточный прогноз.
Нажмите кнопку Вставить столбец прогноза. Значение созданного столбца для каждой строки будет представлять оценку модели вероятности того, что этот автомобиль имеет selling_price выше 1 025 000.
Имея эту вероятность, теперь можно вставить столбец бинарного классификатора — единственный важный параметр, который ещё предстоит определить, — это порог, при котором строка должна быть отнесена к классу is expensive:
=IF(AN2 >= 0.5, 1, 0)
Число 0,5 в приведённой формуле — это обсуждаемый порог. При 0,5 модель обычно даёт наиболее сбалансированное соотношение чувствительности, точности и доли верных. Однако в зависимости от наших целей может подойти другое значение.
Нажмём кнопку Создать лист сводки и рассмотрим детали регрессии.

Помимо свободного члена и коэффициентов, которые присутствуют в сводке любой линейной регрессии, сводный лист логистической регрессии содержит таблицу характеристик точность, чувствительность и доля верных при различных уровнях порога.
Например, если мы хотим, чтобы модель была более точной и избегала ошибочного присвоения класса 1 строкам, мы можем рассмотреть использование порога 0,87 вместо 0,5, потому что точность в этой точке достигает 90% вместо всего лишь 62% для порога 0,5. Однако мы также видим, что при пороге 0,87 чувствительность падает до чуть менее 80%, что значительно меньше почти 93%, достижимых при пороге 0,5.
Аналогично, выбор более низкого порога, например 0,13, может значительно улучшить чувствительность классификатора, достигая почти 99% ценой снижения точности примерно до 40%.
Однако существует возможный способ достичь желаемого уровня точности или чувствительности без ущерба для другой характеристики: создание лучшей модели.
Настройка логистической регрессии
Каждый возможный параметр, обсуждаемый на странице о тонкой настройке линейных регрессий, применим и к логистическим регрессиям, поскольку в основе процесс один и тот же.
Попробуем следующие шаги настройки:
- Применить техники разработки признаков и исключения столбцов, описанные на странице тонкая настройка регрессий.
- Включить 3-кратную перекрёстную проверку.
-
Добавить дополнительные столбцы идентификации производителя так же, как мы делали при подготовке набора данных об автомобилях.
-
Volvo
=IF(ISNUMBER(FIND("Volvo", A2)), 1, 0) - BMW
=IF(ISNUMBER(FIND("BMW", A2)), 1, 0) - Audi
=IF(ISNUMBER(FIND("Audi", A2)), 1, 0) - Mercedes-Benz
=IF(ISNUMBER(FIND("Mercedes-Benz", A2)), 1, 0) - Lexus
=IF(ISNUMBER(FIND("Lexus", A2)), 1, 0) - Jaguar
=IF(ISNUMBER(FIND("Jaguar", A2)), 1, 0) - Jeep
=IF(ISNUMBER(FIND("Jeep", A2)), 1, 0) - Land Rover
=IF(ISNUMBER(FIND("Land Rover", A2)), 1, 0) - Volkswagen
=IF(ISNUMBER(FIND("Volkswagen", A2)), 1, 0)
-
-
Добавить дополнительные производные признаки:
- perceived wear
=Z2 / (Y2 / MAX($Y$2:$Y$8129))
где Z — столбец km_driven, а Y — столбец average price of year.
- depreciated torque N·m
=AU2 * Y2 / MAX($Y$2:$Y$8129)
где AU — столбец torque N·m, а Y — столбец average price of year.
- perceived wear
- Выбрать весь диапазон и открыть инструмент Логистическая регрессия в TableTorch.
- Использовать стратифицированную равномерную случайную выборку со столбцом year stratum в качестве страты.
- Снять отметки со столбцов year, selling_price, is expensive, km_driven, petrol, max power bhp, engine cc, torque N·m, max torque min RPM в списке признаков.
- Нажать Обучить модель.
Созданная модель будет иметь сводку примерно такого вида:
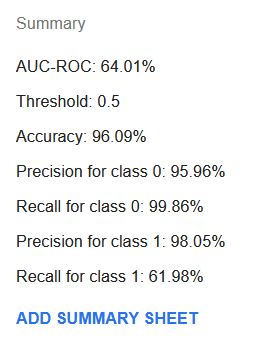
Хотя AUC-ROC стал значительно ниже на уровне 64%, доля верных, чувствительность для класса 0 и точность для класса 1 значительно улучшились. Чувствительность для класса 1 существенно упала до всего лишь 62%, но если мы посмотрим на сводный лист обучения, можно найти порог, например 11%, при котором чувствительность составляет 83%, точность — 89%, а доля верных — 97%.
Новая модель, вероятно, лучше той, что была получена с настройками по умолчанию, но она всё ещё не выглядит как значительное улучшение. Возможно, набору данных потребуются дополнительные исходные признаки, указывающие на дорогой автомобиль, чтобы можно было построить более точную модель.
Стратификация
TableTorch по умолчанию использует стратифицированную равномерную случайную выборку для логистических регрессий, чтобы создать несмещённую модель. Однако это не всегда желательно: качество такой модели в первую очередь окажется оптимизированным под чувствительность недопредставленного класса (1 в случае столбца is expensive, который присвоен только 10% записей).
Следовательно, если используется стратифицированная пропорциональная случайная выборка, регрессия, вероятно, будет в среднем более точной. Для нашего примера использование пропорциональной выборки даст модель с AUC-ROC всего 27%, однако она также будет иметь точность для класса 1 на уровне 98,4% при пороге 0,05 с чувствительностью для класса 1 на уровне 62%. Такая модель может быть не очень хороша в определении каждого дорогого автомобиля, но когда она указывает, что автомобиль дорогой, вероятность того, что это действительно так, высока.
Смотрите также
Google, Google Таблицы, Google Workspace и YouTube являются товарными знаками Google LLC. Gaujasoft TableTorch не связан с Google и не одобрен компанией Google.
Свяжитесь с нами!
Спасибо, что используете или рассматриваете TableTorch!
Точно и полно ли эта страница описывает соответствующую функцию? Действительно ли всё работает так, как здесь описано, или вы столкнулись с проблемой? Есть ли у вас предложения по улучшению?
Пожалуйста, свяжитесь с нами, если у вас есть вопросы.