Datu izlase
TableTorch funkcija Izlase nolasa atlasītā diapazona datus un ievieto jaunu lapu, kas satur atsevišķas sākotnējo datu izlases, kurās rindas tiek atlasītas saskaņā ar norādītajām opcijām.
To var izmantot šādiem mērķiem:
- Sadalīšana: datu sadalīšana atsevišķās treniņu-testa kopās vai vairākās vienāda lieluma kopās, kas noderīgas k-kārtīgai šķērsvalidācijai (k-fold cross-validation).
- Randomizēšana: rindu secības nejaušināšana.
- Stratificēta nejaušā izlase:
- Vienmērīga: sadalēs jābūt vienādam rindu skaitam, kas pieder katrai stratai.
- Proporcionāla: katras stratas īpatsvaram jābūt tādam pašam, kāds tas bija sākotnējā datu kopā katrā izlasē.
- Izlase ar nomaiņu: katrai rindai ir vienāda varbūtība tikt iekļautai rezultātu izlasē, rindu skaits var būt lielāks nekā sākotnējā datu kopā, un ir iespēja, ka tā pati rinda parādās vairāk nekā vienu reizi konkrētā izlasē.
Izlases metodes, kas ir pieejamas Izlase panelī, ir tādas pašas kā lineārajai un loģistiskajai regresijai. Pamatā esošais algoritms arī ir tas pats. Tādējādi Izlase var būt noderīga, lai vizuāli pārskatītu, kā dati tiks sadalīti pirms regresijas veikšanas, kā arī lai veiktu jebkuru citu pētījumu par izlasēm.
Apskatīsim katras pieejamās opcijas pielietojumu transportlīdzekļu datu kopai nākamajās sadaļās.
- Sāciet darbu ar TableTorch
- Treniņu-testa sadalījums
- Stratificēta 3-kāršīga šķērsvalidācijas sadalīšana
- Izlase ar nomaiņu
- Formulas
Sāciet darbu ar TableTorch
- Instalējiet TableTorch Google izklājlapām, izmantojot Google Workspace Marketplace. Vairāk informācijas par sākotnējo iestatīšanu.
- Noklikšķiniet uz TableTorch ikonas
 Google izklājlapu labās puses panelī.
Google izklājlapu labās puses panelī.
Treniņu-testa sadalījums
Atlasiet visu datu kopu un noklikšķiniet uz TableTorch izvēlnes pogas Izlase.
Parādīsies panelis ar izlases opcijām:
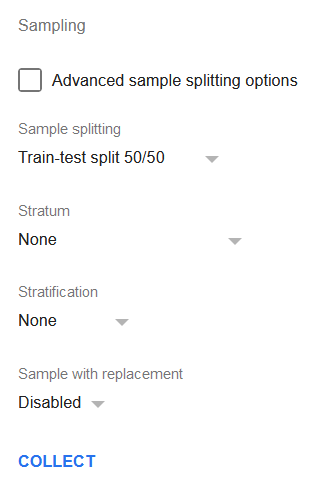
Noklikšķiniet uz pogas Savākt, un TableTorch ievietos jaunu lapu ar divām datu izlasēm, katra sastāv no puses sākotnējās datu kopas rindu.
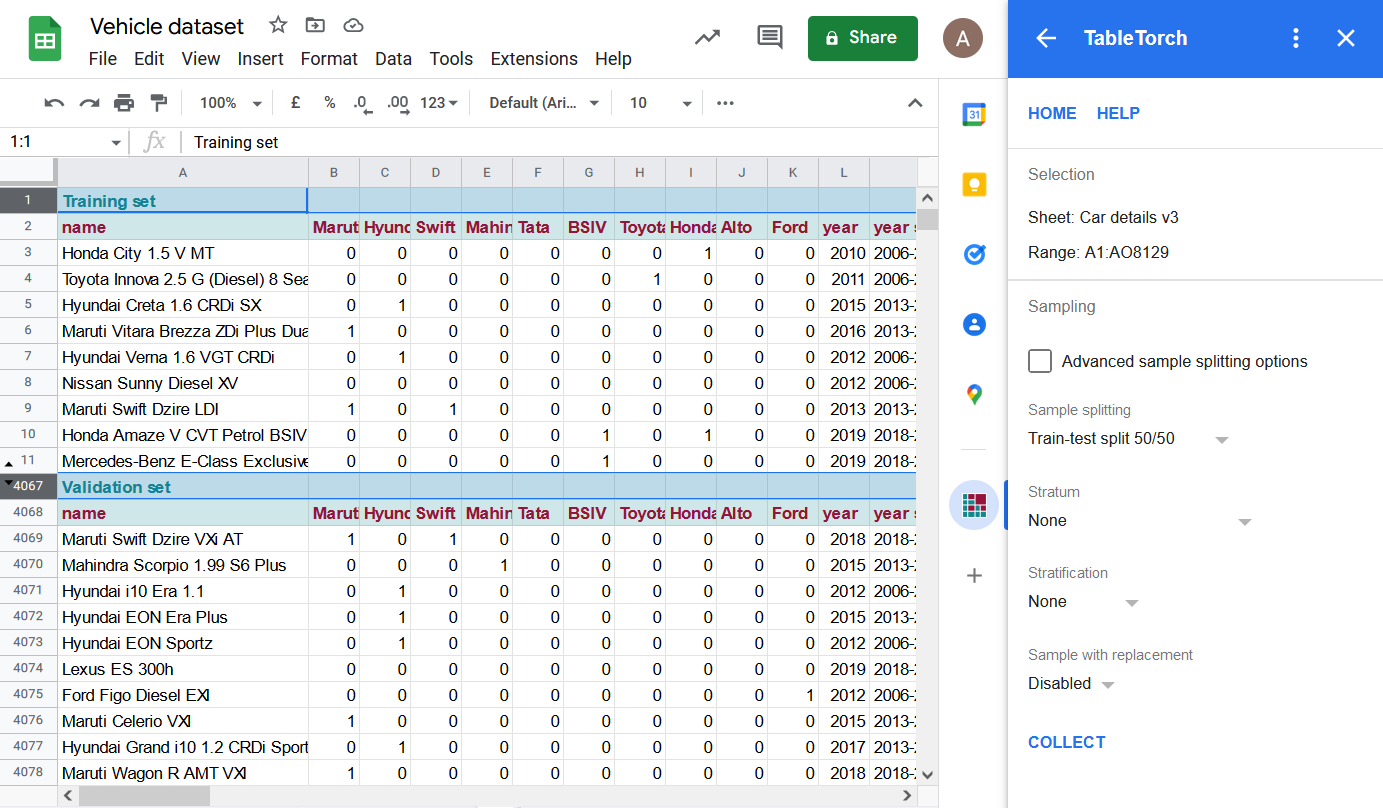
Rindas 12..4066 ir paslēptas iepriekš redzamajā ekrānuzņēmumā, lai parādītu, ka rezultātu lapa satur divas atsevišķas datu kopas ar identisku kolonnu struktūru, galvenes rindu ar kopas identifikāciju, kā arī papildu rindu ar kolonnu nosaukumiem.
Izlase ar nomaiņu netika izmantota, tāpēc katra no kopām satur tikai unikālus ierakstus no sākotnējās datu kopas.
Stratificēta 3-kāršīga šķērsvalidācijas sadalīšana
Izmēģināsim 3-kāršīgu šķērsvalidācijas sadalīšanu ar year stratum kolonnu (skatiet regresiju uzlabošanas lapu par tās formulu) kā stratas kolonnu un stratificētu vienmērīgu nejaušo izlasi. Pilnais opciju kopums ir parādīts zemāk esošajā attēlā.
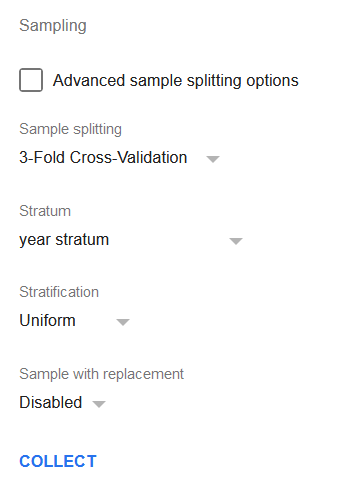
Noklikšķiniet uz pogas Savākt, lai veiktu izlasi.
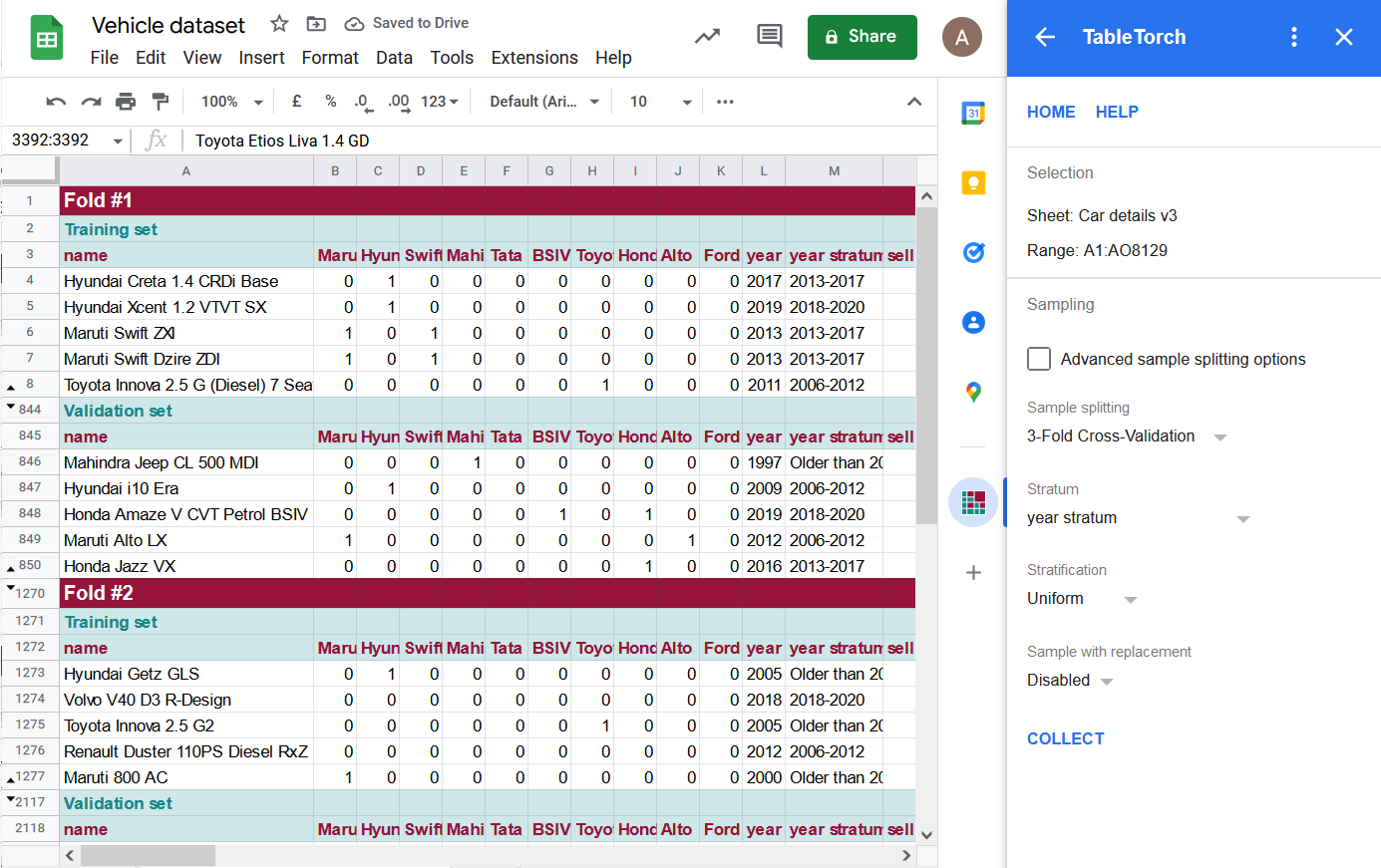
Dažas rindas ir paslēptas iepriekš redzamajā attēlā, lai būtu redzamas kāršu galvenes rindas un to kopas.
TableTorch izveidoja 3 kārtis, katra no tām satur Apmācības datu kopu ar divām trešdaļām datu un Validācijas datu kopu, kas satur unikālu vienu trešdaļu no sākotnējās datu kopas.
Katra strata, ko identificē kolonna year stratum, ir vienmērīgi pārstāvēta katrā no treniņu un validācijas kopām, t.i., rindu skaitam jābūt vienādam. Neliela novirze var rasties, ja rindu skaitu nevar dalīt ar šķērsvalidācijas k parametru (t.i. 3, 5 vai 10) vienmērīgi.
Izlase ar nomaiņu
Nomaiņa ļauj veikt stratificētu nejaušu izlasi, nebaidoties par nepietiekami pārstāvētajām stratām.
Iedomājieties datu kopu ar 200 rindām, kur 40 rindas pieder stratai A un 160 stratai B. Stratificētai vienmērīgai nejaušai izlasei vajadzētu izveidot datu kopu ar identisku rindu skaitu, kas pieder katrai stratai. Tāpēc ar noklusējuma iestatījumiem tā var izveidot tikai datu kopu, kas sastāv no 80 ierakstiem, 40 no A un 40 no B. Jebkura statistiskā analīze, kas jāveic uz izveidotās izlases, zaudēs 120 jeb 75% no rindām, kas pieder stratai B, kas ir būtisks signāla zudums un varētu pasliktināt analīzes pamatotību.
Izlase ar nomaiņu ir paredzēta, lai mazinātu šo trūkumu. Tā to dara, nejauši atlasot rindu no sākotnējās kopas iepriekš noteiktu reižu skaitu. Tādējādi, ja tiek izmantota nomaiņa, stratificētā vienmērīgā nejaušā izlase var izveidot datu kopu ar 160 vai vairāk rindām abām stratām. Tomēr dažas no šīm rindām būs dublikāti, tāpēc šāda veida izlase ir piemērota tikai noteiktai statistiskai analīzei, piemēram, lineārajām regresijām.
Ja nomaiņa ir iespējota, TableTorch izmanto šādu heiristiku, lai aprēķinātu atlasāmo rindu skaitu:
- Definēsim n kā rindu skaitu sākotnējā datu kopā, dalītu ar stratu skaitu. Piemēram, datu kopai ar 240 rindām un 3 stratām n ir 80.
- Ja sākotnējā datu kopā ir mazāk nekā 1000 rindas, tā atlasa n reizinājuma rindas, lai palielinātu iespējas, ka visas sākotnējās rindas nonāks datu kopā. Piemēram, ja n ir 80, TableTorch visticamāk atlasīs vismaz 200 rindas katrai stratai, atkarībā no kolonnu skaita un citiem apstākļiem.
- Pretējā gadījumā tā atlasa n rindas katrai stratai. Tas var izraisīt to, ka dažas rindas tiek izlaistas no rezultātu izlases, tomēr tas ir nepieciešams, lai samazinātu maksimālā izpildes laika pārsniegšanas varbūtību vai netīšu vairāk nekā 5 miljonu šūnu ierobežojuma pārsniegšanu Google izklājlapās.
Formulas
TableTorch kopē datus rezultātu datu kopā pēc vērtībām, t.i., formulas netiek kopētas. Tas tiek darīts, lai paātrinātu procesu un izvairītos no kvotu pārsniegšanas. Tiek pieņemts, ka izveidotā lapa ir pagaidu rakstura un ir noderīga turpmākām regresijām vai citām datu manipulācijām, nevis formulu eksperimentiem.
Skatīt arī Vikipēdijā (angļu valodā):
Google, Google Izklājlapas, Google Workspace un YouTube ir Google LLC preču zīmes. Gaujasoft TableTorch nav saistīts ar Google un to neveicina Google.
Pasakiet mums!
Paldies, ka izmantojat vai apsverot izmantot TableTorch!
Vai šī lapa precīzi un atbilstoši apraksta attiecīgo funkciju? Vai tā patiešām darbojas tā, kā šeit izskaidrots, vai arī ir kāda problēma? Vai jums ir kādi ieteikumi, kā mēs varētu uzlaboties?
Lūdzu, paziņojiet mums, ja jums ir kādi jautājumi.
- E-pasts: ___________
- Facebook lapa
- Twitter profils