Feinabstimmung von Regressionen
Die lineare Regression, die als Beispiel auf dieser Seite durchgeführt wurde, hat gezeigt, dass TableTorch auch mit Standardeinstellungen ein Modell mit angemessener Leistung erstellen kann. Lässt sich diese Leistung jedoch mit einer anderen Konfiguration noch verbessern? Finden wir es heraus.
- Lernoptionen
- Sampling-Optionen
- Feature-Engineering
- year stratum
- Berücksichtigung von Inflation und Wertminderung
- depreciated max power bhp (AG)
- Anpassen des Modells mit neuen Merkmalen
- Datenleck
- Fazit
Wir werden weiterhin den Fahrzeugdatensatz verwenden und versuchen, den Wert der Spalte selling_price vorherzusagen.
TableTorch bietet zwei Abschnitte mit Regressionsoptionen: Lernoptionen, die den Regressionsalgorithmus beeinflussen, und Sampling-Optionen, die das Sampling des ursprünglichen Datensatzes steuern. Letztere teilen den Datensatz in separate Trainings- und Testmengen auf und ermöglichen optional eine K-Fold-Kreuzvalidierung, die mehrere Regressionen durchführt und automatisch das beste Modell auswählt.
Sehen wir uns zunächst die verfügbaren Lernoptionen an.
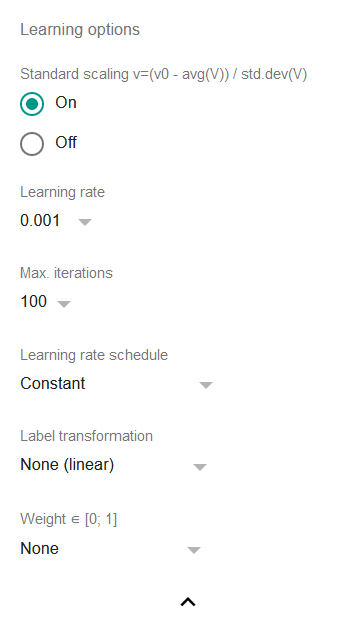
Lernoptionen
-
Standard scaling: wenn aktiviert, werden alle Merkmale und die Zielvariable vor dem Anpassen des Modells standardskaliert, d.h. die Regression arbeitet mit Werten, die mit der Formel vorverarbeitet wurden
v=(v0 - average(V)) / std.dev(V)wobei
v0der ursprüngliche Wert undVdie Menge aller vorhandenen Werte ist.Standardskalierung ist eine weithin akzeptierte Praxis für lineare Regressionen und es ist im Grunde nur dann sinnvoll, sie auszuschalten, wenn die Originaldaten bereits skaliert wurden.
-
Learning rate: ein entscheidend wichtiger Parameter jedes Gradientenabstiegsalgorithmus. Er definiert das Tempo, mit dem der Algorithmus die Koeffizienten ändert, um Konvergenz zu erreichen. Höhere Werte können die Regression beschleunigen, lassen den Algorithmus aber leichter um bestimmte Werte schwanken. Niedrigere Werte verlangsamen den Prozess und können dazu führen, dass die Anzahl der Iterationen bis zur Konvergenz unannehmbar groß wird. Als Faustregel funktionieren in den meisten Fällen 0,01 oder 0,001 gut; TableTorch bietet aber auch andere Optionen.
-
Max. iterations: maximale Anzahl von Iterationen (Epochen), die während einer Regression durchgeführt werden sollen. Normalerweise ist es nicht sinnvoll, diesen Parameter zu ändern, da der Standardwert von 100 bereits recht hoch ist und die Regression ohnehin stoppt, sobald die Verbesserung der letzten Iterationen weniger als 1E−6 (0,000001) des relativen Fehlers beträgt.
-
Learning rate schedule: wenn nicht konstant, verringert sich die Lernrate nach jeder Epoche. Dadurch kann die Regression auch sehr schwache Signale in den Daten noch erfassen.
-
Label transformation: wenn nicht-linear, wird die Zielvariable vor dem Anpassen des Modells transformiert. So lassen sich lineare Regressionen auch auf Zielvariablen durchführen, die keine lineare Abhängigkeit von den unabhängigen Variablen aufweisen — ohne dass zusätzliche Spalten eingeführt werden müssen.
a) Die Exponential-Variante geht davon aus, dass die Zielvariable eine exponentielle Abhängigkeit von den ausgewählten Merkmalen hat, und sagt eine Potenz von e statt eines linearen Werts voraus.
b) Die Logistic-Variante geht davon aus, dass die Zielvariable im Bereich [0; 1] liegt und eine binäre Klassifizierung darstellt, ob eine Zeile zu einer bestimmten Klasse bzw. einem Ereignis gehört. Wir empfehlen, statt dieser Option das Werkzeug für logistische Regression in TableTorch zu verwenden, da es zudem eine nützlichere Zusammenfassung liefert.
-
Weight: wenn angegeben, verwendet die Regression die Methode der gewichteten kleinsten Quadrate anstelle der gewöhnlichen kleinsten Quadrate. In der Praxis beeinflusst die als weight angegebene Spalte die Lernrate für jede einzelne Zeile und kann verwendet werden, um den Einfluss von Ausreißerzeilen auszuschließen oder zu reduzieren.
Setzen wir die Label transformation auf Exponential und führen die Regression erneut durch.

Überraschenderweise haben sich sowohl die R²- als auch die MAE-Metriken dramatisch verbessert, wobei R² 0,75 erreicht und MAE sich auf 136.000 fast halbiert hat.
Das könnte darauf hindeuten, dass tatsächlich eine exponentielle Beziehung zwischen dem selling_price und den Fahrzeugmerkmalen besteht. Allerdings fehlen im Fahrzeugdatensatz Merkmale wie wirtschaftliche Inflation oder akkumulierte Abschreibungsrate, sodass es möglicherweise zu früh ist, eine Schlussfolgerung über die Art der Abhängigkeit zwischen den Fahrzeugmerkmalen und dem selling_price zu ziehen.
Setzen wir die Label transformation kurz wieder auf None, um uns nun die Sampling-Optionen anzusehen.
Sampling-Optionen
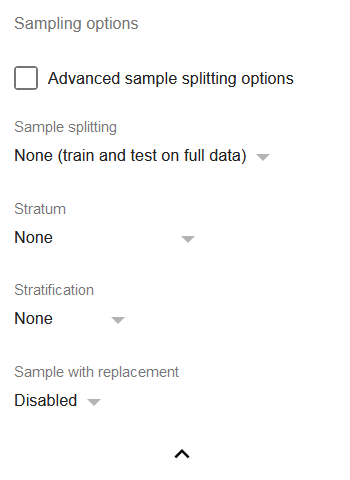
- Advanced sample splitting options: aktivieren Sie diese Option, wenn Sie den Trainingsanteil für eine Trainings-/Test-Aufteilung oder k für k-Fold-Kreuzvalidierung genauer angeben möchten.
-
Sample splitting: eine Reihe der am häufigsten verwendeten Datensatz- Aufteilungstechniken für Regressionen:
a) Train-test split 50/50: teilt den Datensatz so auf, dass nur 50 % der Daten für das Training verwendet werden.
b) Train-test split 80/20: wie (a), aber mit einem höheren Anteil an Daten für das Training.
c) 3-Fold Cross-Validation: teilt den Datensatz in drei gleich große Stichproben A, B und C auf und führt dann drei verschiedene Regressionen durch: die erste wird auf den Stichproben (A, B) trainiert und auf Stichprobe C validiert, die zweite wird auf den Stichproben (B, C) trainiert und auf Stichprobe A validiert, die dritte wird auf den Stichproben (A, C) trainiert und auf Stichprobe B validiert, dann wird das Modell mit dem höchsten R² ausgewählt.
d) 5-Fold Cross-Validation und 10-Fold Cross-Validation: im Allgemeinen das gleiche wie (c), aber mit einer höheren Anzahl von Folds, d.h. Anzahl der durchzuführenden Regressionen.
-
Stratum: ermöglicht die Auswahl einer Spalte, die das Stratum angibt, zu dem eine Zeile gehört.
-
Stratification: Sobald eine der Aufteilungsoptionen aktiv ist, können Sie zusätzlich eine Schichtungsstrategie wählen:
a) None: Zeilen werden zufällig auf die Aufteilungen verteilt.
b) Stratified proportional: jede Schicht ist in jeder Aufteilung im gleichen Verhältnis vertreten wie im gesamten Datensatz.
c) Stratified uniform: alle Schichten haben die gleiche Anzahl von Zeilen in jeder Aufteilung. Wenn Sampling mit Ersetzung deaktiviert ist, wird die Anzahl der Zeilen durch die Größe der kleinsten Schicht bestimmt. Andernfalls richtet sie sich nach der Größe der größten Schicht. Daher ist es normalerweise sinnvoll, die Ersetzung zu aktivieren, wenn das stratifizierte uniforme Sampling verwendet wird.
- Sample with replacement: wenn aktiviert, werden die Aufteilungen mit Ersetzung gezogen, d.h. dieselbe Zeile kann mehrfach in einer Aufteilung vorkommen. Das ist besonders nützlich für unausgeglichene Datensätze, in denen eine bestimmte Schicht unterrepräsentiert ist. Mit Ersetzung lässt sich die zufällige uniforme Schichtung verwenden, ohne durch eine zu geringe Zeilenanzahl Signal zu verlieren.
Führen wir die selling_price-Regression erneut mit der sample splitting-Option auf 3-Fold Cross-Validation durch.

Interessanterweise hat sich das R² deutlich verbessert und erreicht 0,83, während MAE auf etwa 283.000 gestiegen ist. Dies mag verwirrend erscheinen, da es darauf hindeutet, dass das Modell jetzt wahrscheinlich die Varianz besser erfasst, obwohl der durchschnittliche absolute Fehler gestiegen ist.
Bedenken Sie jedoch, dass diese Ergebnisse erzielt wurden, indem nur auf zwei Dritteln der Daten trainiert wurde. Das bedeutet, dass sich das Modell gegenüber Daten, die es während des Anpassungsprozesses nicht gesehen hat, als robust erwiesen hat. Genau deshalb ist es gängige Praxis, die K-Fold-Kreuzvalidierung in praktisch jedem Fall einzusetzen — sie schützt das Modell vor Überanpassung.
Feature-Engineering
Bei der Aufbereitung des Fahrzeugdatensatzes haben wir den Datensatz bereits angepasst, um textuelle Informationen in numerische Daten umzuwandeln. Wir haben jedoch keine Hilfsmerkmale eingeführt, die der Regression helfen könnten.
Darüber hinaus haben wir der Korrelationsmatrix des Datensatzes nicht viel Aufmerksamkeit geschenkt, obwohl es entscheidend sein könnte, hochkorrelierte Variablen aus der Regression auszuschließen.
Das Werkzeug Korrelationsmatrix erzeugt die folgende Matrix für den Datensatz:

Die Koeffizienten zeigen, dass einige der Spalten von der Regression der selling_price-Spalte ausgeschlossen werden können:
- max torque max RPM aufgrund seiner hohen Korrelation mit max torque min RPM und seiner vernachlässigbaren Korrelation mit selling price.
- petrol aufgrund seiner sehr hohen Korrelation mit diesel.
- engine cc aufgrund seiner Korrelation mit max power bhp, wobei letzterer eine höhere Korrelation mit selling_price aufweist.
Wählen wir die Spalten max torque max RPM, petrol und engine cc ab, bevor wir die Regression durchführen.
Aktivieren Sie die 3-Fold-Kreuzvalidierung und klicken Sie auf Fit model, um die Regression durchzuführen.

Die Leistung der Regression hat sich weder verbessert noch verschlechtert, was ein gutes Zeichen ist: je weniger Merkmale für dieselbe Modellqualität nötig sind, desto besser.
Versuchen wir nun, eine Hypothese darüber aufzustellen, welche zusätzlichen Merkmale sich aus den vorhandenen Variablen ableiten ließen, um der Regression dabei zu helfen, die Varianz der Zielvariable zu erklären.
year stratum
Wenn wir die Anzahl der Zeilen pro year betrachten, stellt sich heraus, dass es viele Jahre mit nur wenigen Datensätzen gibt.
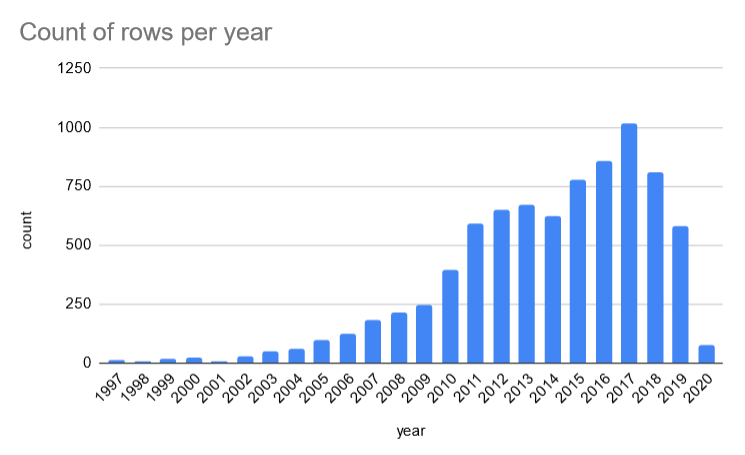
Es könnte sinnvoll sein, die Datensätze in nur wenige Kohorten oder Schichten zu gruppieren:
- 1-3 Jahre (
year >= 2018); - 4-8 Jahre (
AND(year >= 2013, year < 2018)); - 9-15 Jahre (
AND(year >= 2006, year < 2013); - mehr als 15 Jahre alt (
year < 2006).
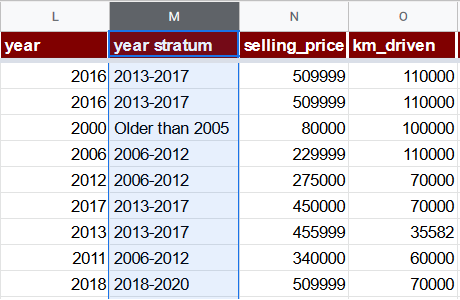
Fügen wir eine Spalte year stratum direkt nach der year (L) Spalte mit der Formel ein:
=IFS(L2 >= 2018, "2018-2020", L2 >= 2013, "2013-2017", L2 >= 2006, "2006-2012", TRUE, "Older than 2005")
Beachten Sie, dass diese Spalte einen textuellen statt eines numerischen Wertes enthält. Das ist beabsichtigt: Sie wird nicht direkt in einer Regression verwendet, sondern hilft bei der Ableitung anderer Merkmale und kommt zudem beim geschichteten uniformen zufälligen Sampling zum Einsatz.
Berücksichtigung von Inflation und Wertminderung
Da der Zustand von Fahrzeugen sich mit dem Alter typischerweise verschlechtert und neuere Modelle zugleich immer ausgefeiltere Funktionen erhalten, bietet es sich an, eine Art Inflation + Wertminderung-Merkmal einzuführen, um die durchschnittliche Wirkung dieser Phänomene auf eine bestimmte Zeile abzuschätzen.
Eine Möglichkeit, dies zu tun, wäre die Einführung zusätzlicher Daten in den Datensatz, die die akkumulierte Fahrzeugpreisinflation in einem bestimmten Jahr sowie die Abschreibungsrate für ein bestimmtes Modell darstellen. Manchmal könnten jedoch zusätzliche Daten nicht ohne Weiteres verfügbar sein oder deren Beschaffung könnte zusätzliche Kosten verursachen.
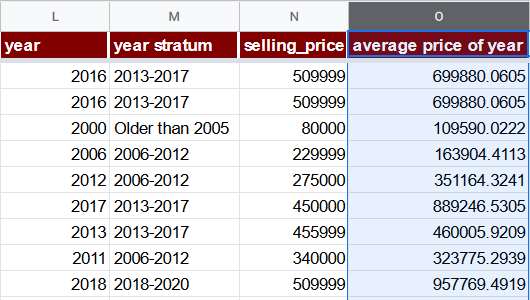
Verwenden wir daher eine andere Option: eine average price of year (O) Spalte. Ihre Formel wird einfach den Durchschnittspreis aller Fahrzeuge aggregieren, die in einem bestimmten Jahr produziert wurden. Da es für Jahre vor 2006 weniger als 100 Datensätze pro Jahr gibt, verwenden wir für sie den Durchschnittspreis der „Older than 2005“-Schicht. Beachten Sie, dass die Einführung eines solchen Merkmals eine Form des Datenlecks darstellt, die wir später auf dieser Seite noch besprechen werden.
=IF(L2 <= 2005, AVERAGEIF($M$2:$M$8129, "Older than 2005", $N$2:$N$8129), AVERAGEIF($L$2:$L$8129, L2, $N$2:$N$8129))
depreciated max power bhp (AG)
In allen selling_price-Regressionen, die wir bisher durchgeführt haben, wurde der bedeutendste Koeffizient stets dem max power bhp-Merkmal zugewiesen.
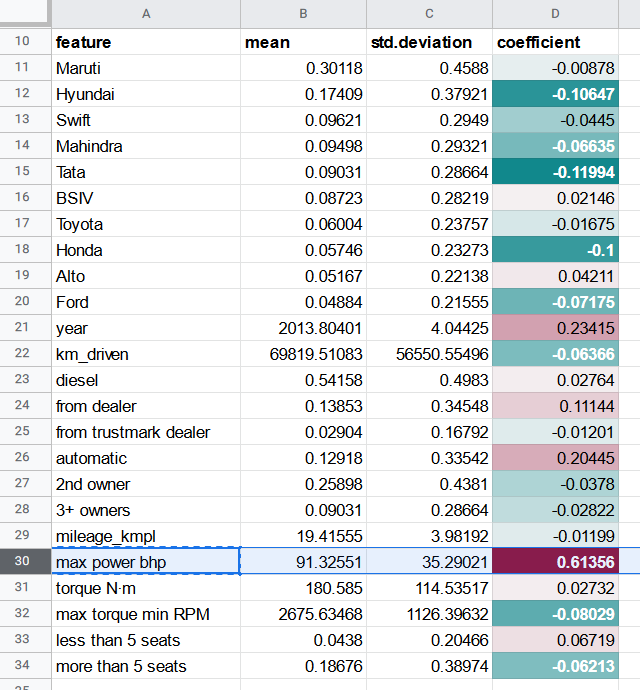
Da die Leistung eines Autos jedoch mit der Zeit nachlässt, entspricht eine Angabe von 100 bhp für ein im Jahr 2000 produziertes Auto möglicherweise nicht derselben tatsächlichen Leistung wie 100 bhp bei einem 2020 produzierten Auto.
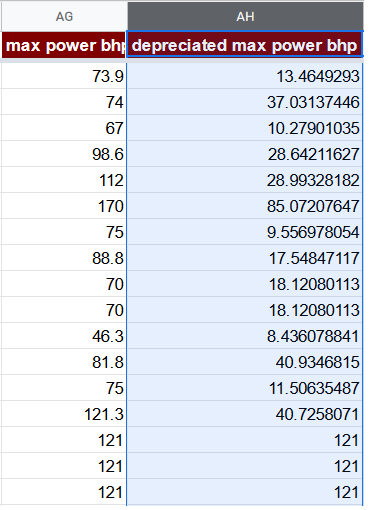
Eine mögliche Korrektur des max power bhp-Merkmals in unserem Fall besteht darin, es mit dem average price of year zu multiplizieren und anschließend durch das Maximum von average price of year zu teilen. Dieses Merkmal stünde dann für den wahrgenommenen Wert eines max power bhp bei einem Auto eines bestimmten Alters.
=AG2 * O2 / MAX($O$2:$O$8129)
Anpassen des Modells mit neuen Merkmalen
Die Korrelationsmatrix bezüglich selling_price, year und der abgeleiteten Merkmale sieht folgendermaßen aus:
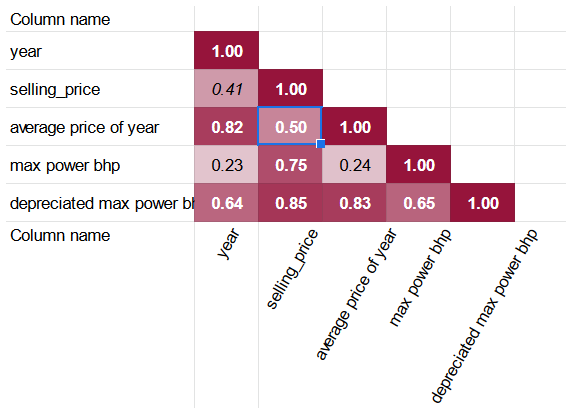
Die gute Nachricht ist, dass die depreciated max power bhp-Spalte einen höheren Korrelationskoeffizienten mit selling_price hat als die unveränderte max power bhp-Spalte. Darüber hinaus ist average price of year auch signifikanter mit selling_price korreliert als die einfachere year-Spalte.
Fügen wir diese neuen Merkmale zur Regression hinzu und entfernen gleichzeitig die Spalten year und max power bhp. Die Spalten max torque max RPM, petrol und engine cc sollten ebenfalls in der Merkmalsliste deaktiviert werden, wie oben besprochen. Außerdem sollte die 3-Fold Cross-Validation-Einstellung ebenfalls aktiviert werden.
Da es jetzt auch eine year stratum-Spalte gibt, sollte sie als Stratum-Spalte festgelegt werden und die Schichtung sollte auf uniform gesetzt werden. Dies stellt sicher, dass jeder Fold genau die gleiche Anzahl von Zeilen aus jeder Schicht enthält, wodurch die Verzerrung des Modells gegenüber neueren oder älteren Fahrzeugen reduziert wird.
Die gesamte Konfiguration der Regression wird unten gezeigt.
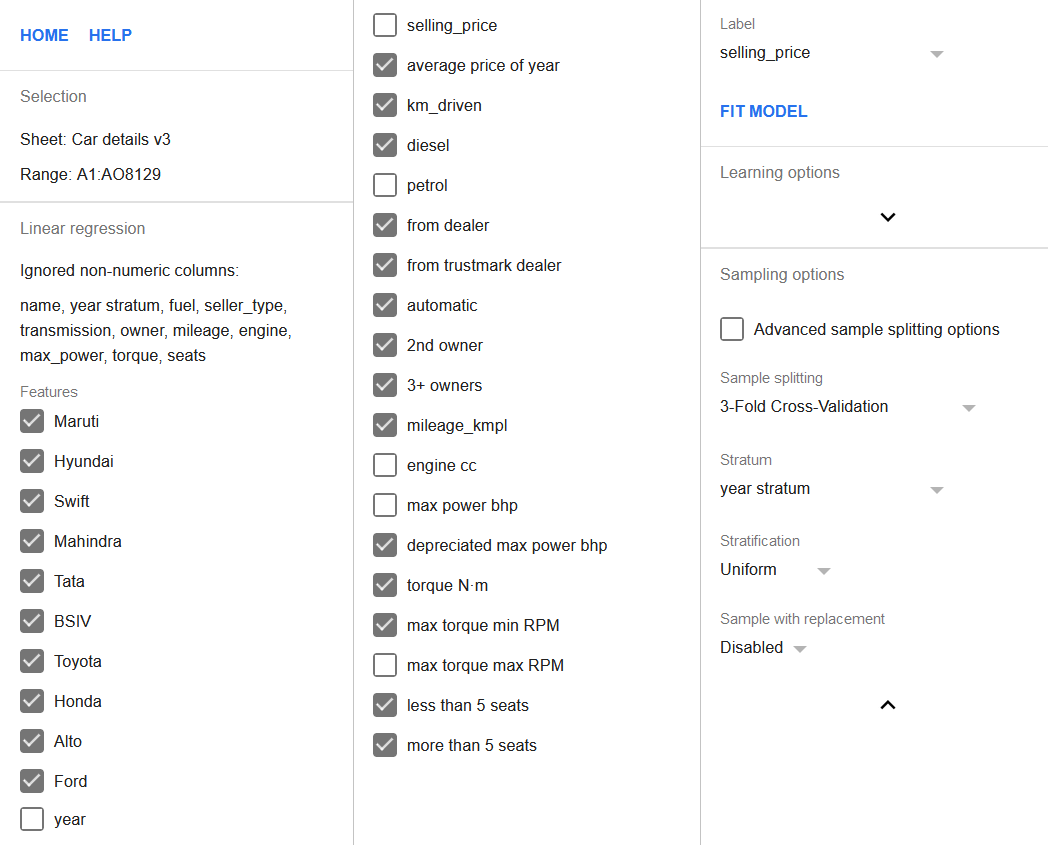
Klicken Sie auf die Schaltfläche Fit model, um die Regression durchzuführen.

Faszinierenderweise hat R² fast den bestmöglichen Wert von 0,99 erreicht. Sowohl RMSE als auch MAE werden deutlich niedriger als bei der Regression mit Standardeinstellungen und ohne abgeleitete Merkmale.
Wenn wir außerdem eine Vorhersagespalte und eine relative error-Spalte
=ABS((AP2 - N2) / N2) einfügen (wobei N der selling_price
und AP2 die prediction ist) und dann nach dem relative error sortieren,
sehen wir, dass 19 % der Zeilen einen Vorhersagefehler von 10 % oder weniger
des beobachteten selling_price aufweisen und der mediane relative Fehler etwa
28,8 % beträgt.
Datenleck
Beachten Sie, dass die Ableitung eines Merkmals aus der abhängigen Variablen, wie wir es mit der average price of year-Spalte getan haben, ein Datenleck einführt. Damit ist eine Situation gemeint, in der die Zielvariable anhand von Daten vorhergesagt wird, die sie bereits selbst enthalten. Das kann die Anwendung des Modells auf neue Daten erschweren oder sogar unmöglich machen.
Der average price of year könnte beispielsweise in einen separaten
Bereich verschoben werden, und für die neuen Daten könnten wir die LOOKUP-Funktion verwenden, um den
Wert des Merkmals abzurufen, da das AVERAGEIF nicht praktikabel ist, weil es
keine beobachteten Werte für den selling_price gibt. Wenn wir jedoch
eine Zeile mit einem Wert von year antreffen, der während des
Trainings des Modells nicht beobachtet wurde, wäre es unmöglich, den entsprechenden
average price of year zu ermitteln, und man müsste stattdessen auf eine bestmögliche
Schätzung zurückgreifen, z. B. den Wert für das nächstgelegene Jahr.
Daher müssen die verbesserten Metriken des feinabgestimmten Modells mit Vorsicht bewertet werden: Es könnte zum Zeitpunkt der Vorhersage nicht so gut funktionieren, wenn einige der abgeleiteten Merkmale nicht zuverlässig ermittelt werden können.
Fazit
Wir haben gezeigt, dass die Optionen, die TableTorch für die Feinabstimmung des Regressionsprozesses bietet, zusammen mit etwas Feature-Engineering zu einem robusteren und zuverlässigeren Modell führen können als die bloße Verwendung der Standardeinstellungen. Es gibt immer Raum für Verbesserung, und auch bei der Modellierung des Fahrzeugdatensatzes lässt sich noch einiges erreichen.
Eine Möglichkeit zur Verbesserung des Modells könnte zum Beispiel darin bestehen, ihm eine andere Frage zu stellen. Anstatt etwa den genauen selling_price vorherzusagen, könnten wir vorhersagen, ob ein Fahrzeug für einen Preis über einem bestimmten Schwellenwert verkauft würde oder nicht. TableTorch bietet ein geeignetes Werkzeug zum Anpassen eines Modells, das auf diese Art von Fragen spezialisiert ist, die logistische Regression.
Siehe auch auf Wikipedia:
- Learning rate (auf Englisch)
- Geschichtete Zufallsstichprobe
- Kreuzvalidierungsverfahren
- Data leakage (auf Englisch)
- Feature engineering (auf Englisch)
Google, Google Tabellen, Google Workspace und YouTube sind Marken von Google LLC. Gaujasoft TableTorch ist nicht mit Google verbunden und wird nicht von Google unterstützt.
Ihr Feedback ist uns wichtig!
Vielen Dank, dass Sie TableTorch verwenden oder in Betracht ziehen!
Beschreibt diese Seite die Funktion korrekt und verständlich? Funktioniert sie tatsächlich so, wie hier beschrieben, oder gibt es ein Problem? Haben Sie Verbesserungsvorschläge?
Bei Fragen können Sie sich jederzeit gerne an uns wenden.
- E-Mail: ___________
- Facebook-Seite
- Twitter-Profil