Тонкая настройка регрессий
Линейная регрессия, выполненная в качестве примера на этой странице, показала, что TableTorch даже с настройками по умолчанию способен построить модель с приемлемым качеством. Однако может ли это качество быть ещё выше при иной конфигурации? Давайте выясним.
- Параметры обучения
- Параметры выборки
- Конструирование признаков
- year stratum
- Учёт инфляции и амортизации
- depreciated max power bhp (AG)
- Подгонка модели с новыми признаками
- Утечка данных
- Заключение
Мы продолжим работу с набором данных об автомобилях и попытаемся предсказать значение столбца selling_price.
TableTorch предоставляет два раздела параметров регрессии: параметры обучения, влияющие на алгоритм регрессии, и параметры выборки, управляющие процессом формирования выборки из исходного набора данных, разбиения его на отдельные обучающую и валидационную выборки, а также опциональным использованием K-кратной перекрёстной проверки, которая выполняет несколько регрессий и автоматически выбирает лучшую модель.
Начнём с изучения доступных параметров обучения.
Параметры обучения
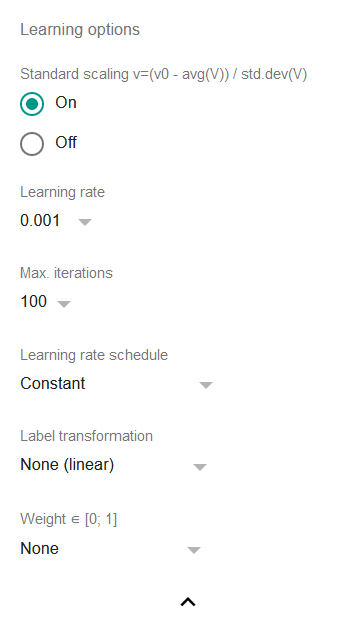
-
Standard scaling: если включено, то все признаки и метка будут стандартно масштабированы перед подгонкой модели, т.е. регрессия будет работать со значениями, предобработанными по формуле
v=(v0 - average(V)) / std.dev(V)где
v0— исходное значение, аV— множество всех имеющихся значений.Стандартное масштабирование является широко принятой практикой для линейных регрессий, и отключать его имеет смысл лишь в том случае, если исходные данные уже были масштабированы.
-
Learning rate: критически важный параметр любого алгоритма градиентного спуска. Он определяет темп, с которым алгоритм изменяет коэффициенты в стремлении к сходимости. Высокие значения могут ускорить регрессию, однако сделают её более склонной к осцилляциям вокруг определённых уровней. Низкие значения замедляют процесс и могут даже привести к ситуации, когда число итераций до достижения сходимости окажется недопустимо большим. Как правило, значения 0,01 или 0,001 хорошо подходят для большинства ситуаций, однако TableTorch предлагает и другие варианты.
-
Max. iterations: максимальное число итераций (эпох), выполняемых в ходе регрессии. Изменять этот параметр обычно нецелесообразно, так как значение по умолчанию 100 достаточно велико, а регрессия всё равно останавливается, как только улучшение за последние несколько итераций составит менее 1E-6 (0,000001) относительной ошибки.
-
Learning rate schedule: если не постоянный, уменьшает скорость обучения после каждой эпохи соответствующим образом. Это может позволить регрессии уловить даже слабый сигнал в данных.
-
Label transformation: если нелинейная, преобразует метку перед обучением на ней. Это позволяет выполнять линейные регрессии для меток, не обладающих линейной зависимостью от независимых переменных, без введения дополнительных столбцов.
a) Вариант Exponential предполагает, что метка имеет экспоненциальную зависимость от выбранных признаков, и пытается предсказать степень числа e, а не линейное значение.
b) Вариант Logistic предполагает, что метка находится в диапазоне [0; 1] и обозначает бинарную классификацию принадлежности строки определённому классу или событию. Рекомендуется использовать инструмент логистической регрессии TableTorch вместо этого варианта, поскольку он также формирует более наглядную сводку результатов.
-
Weight: если указан, регрессия использует метод взвешенных наименьших квадратов вместо обычных наименьших квадратов. На практике столбец, заданный в качестве weight, влияет на скорость обучения для каждой конкретной строки и может использоваться для исключения или снижения влияния выбросов.
Установим параметр Learning transformation в значение Exponential и выполним регрессию заново.

Удивительно, но метрики R² и MAE улучшились кардинально: R² достиг 0,75, а MAE почти вдвое снизился до 136 000.
Это может свидетельствовать о том, что между selling_price и характеристиками автомобиля действительно существует экспоненциальная зависимость. Однако в наборе данных об автомобилях отсутствуют такие признаки, как экономическая инфляция или накопленный коэффициент амортизации, поэтому делать выводы о характере зависимости между характеристиками автомобиля и selling_price ещё преждевременно.
Вернёмся на мгновение назад и сбросим параметр Learning transformation обратно в None, чтобы изучить параметры выборки.
Параметры выборки
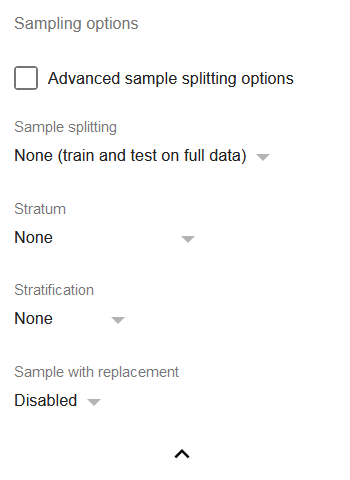
- Advanced sample splitting options: отметьте, если хотите более точно задать долю обучающей выборки при разбиении на обучающую и валидационную выборки или значение k для K-кратной перекрёстной проверки.
-
Sample splitting: набор наиболее часто используемых методов разбиения набора данных для регрессий:
a) Train-test split 50/50: делит набор данных так, что только 50% данных используется для обучения.
b) Train-test split 80/20: аналогично (a), но с большей долей данных, используемых для обучения.
c) 3-Fold Cross-Validation: делит набор данных на три выборки A, B и C равного размера, а затем выполняет три разные регрессии: первую обучает на выборках (A, B) и проверяет на выборке C; вторую обучает на выборках (B, C) и проверяет на выборке A; третью обучает на выборках (A, C) и проверяет на выборке B. Затем выбирается модель с наибольшим R².
d) 5-Fold Cross-Validation и 10-Fold Cross-Validation: в целом аналогично (c), но с большим числом блоков, т.е. числом выполняемых регрессий.
-
Stratum: позволяет выбрать столбец, идентифицирующий страту, к которой принадлежит строка.
-
Stratification: если выбран один из вариантов разбиения, можно выбрать одну из стратегий стратификации:
a) None: строки включаются в каждое разбиение случайным образом.
b) Stratified proportional: каждая страта представлена в каждом разбиении в той же пропорции, что и в исходном наборе данных.
c) Stratified uniform: все страты имеют одинаковое количество строк в каждом разбиении. Если выборка без замены отключена, количество строк определяется числом строк в наименьшей страте. В противном случае количество строк определяется числом строк в наибольшей страте. Поэтому, как правило, имеет смысл включить замену при использовании стратифицированной равномерной выборки.
- Sample with replacement: если включено, каждое разбиение будет формироваться с заменой, т.е. существует вероятность того, что одна и та же строка появится в разбиении дважды. Это особенно полезно для несбалансированных наборов данных, где отдельная страта недопредставлена. При использовании замены можно применять стратифицированную равномерную выборку и избегать потери сигнала из-за малого числа строк.
Выполним регрессию selling_price снова, установив параметр sample splitting в значение 3-Fold Cross-Validation.

Интересно, что R² значительно улучшился, достигнув 0,83, тогда как MAE вырос приблизительно до 283 000. Это может поначалу показаться противоречивым, поскольку указывает на то, что модель теперь, вероятно, лучше объясняет дисперсию, хотя средняя абсолютная ошибка возросла.
Однако следует помнить, что эти результаты были получены при обучении лишь на двух третях данных. Это означает, что данная модель продемонстрировала устойчивость к данным, которые она не видела в процессе обучения. Именно поэтому K-кратная перекрёстная проверка является широко распространённой практикой практически в любом случае — она защищает модель от переобучения.
Конструирование признаков
В ходе подготовки набора данных об автомобилях мы уже модифицировали набор данных, чтобы преобразовать текстовую информацию в числовые данные. Однако мы не вводили никаких вспомогательных признаков, способных помочь регрессии.
Кроме того, мы не уделили должного внимания корреляционной матрице набора данных, тогда как исключение сильно скоррелированных переменных из регрессии может оказаться принципиально важным.
Инструмент Корреляционная матрица строит следующую матрицу для данного набора данных:

Коэффициенты показывают, что ряд столбцов может быть исключён из регрессии столбца selling_price:
- max torque max RPM — из-за высокой корреляции с max torque min RPM и пренебрежимо малой корреляции с selling price.
- petrol — из-за высоко значимой корреляции с diesel.
- engine cc — из-за корреляции с max power bhp, где последний имеет более высокую корреляцию с selling_price.
Снимем отметку со столбцов max torque max RPM, petrol и engine cc перед выполнением регрессии.
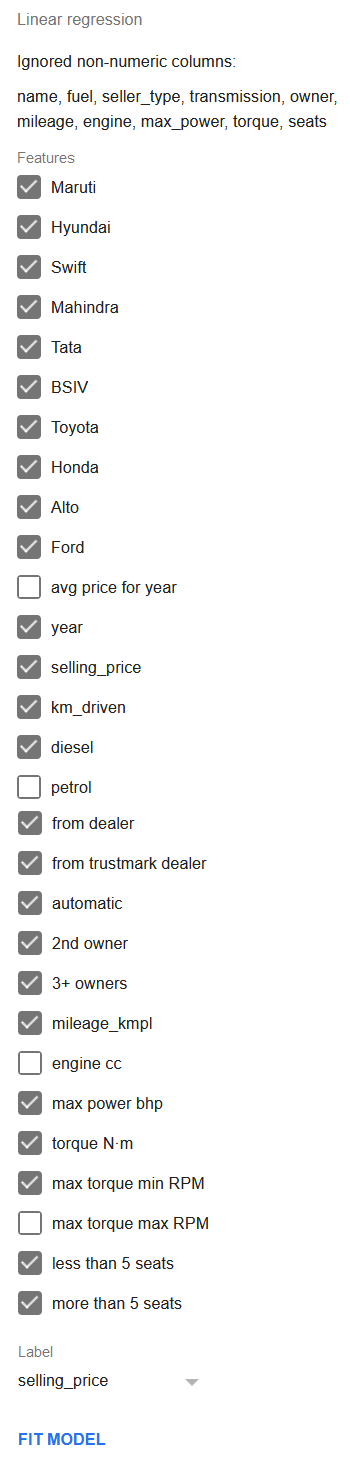
Включите 3-кратную перекрёстную проверку и нажмите Fit model для выполнения регрессии.

Качество регрессии не улучшилось и не ухудшилось, что является хорошим знаком: чем меньше признаков требуется для построения модели с тем же качеством, тем лучше.
Теперь попробуем сформулировать гипотезу о том, какие дополнительные признаки можно вывести из уже имеющихся переменных таким образом, чтобы помочь регрессии объяснить дисперсию в метке.
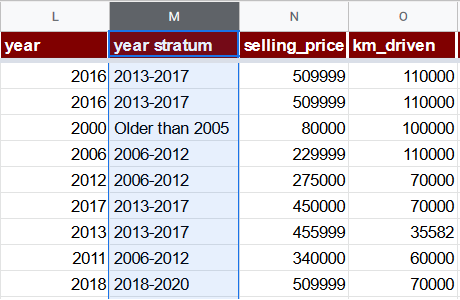
year stratum
Если рассмотреть количество строк по значению year, окажется, что для многих лет существует лишь несколько записей.
Имеет смысл сгруппировать записи всего в несколько когорт или страт:
- 1–3 года (
year >= 2018); - 4–8 лет (
AND(year >= 2013, year < 2018)); - 9–15 лет (
AND(year >= 2006, year < 2013); - более 15 лет (
year < 2006).
Вставим столбец year stratum непосредственно после столбца year (L) со следующей формулой:
=IFS(L2 >= 2018, "2018-2020", L2 >= 2013, "2013-2017", L2 >= 2006, "2006-2012", TRUE, "Older than 2005")
Обратите внимание, что этот столбец имеет текстовое, а не числовое значение. Это правильно: он не будет использоваться непосредственно в регрессии, а поможет в выводе других признаков и также будет применяться при стратифицированной равномерной случайной выборке.
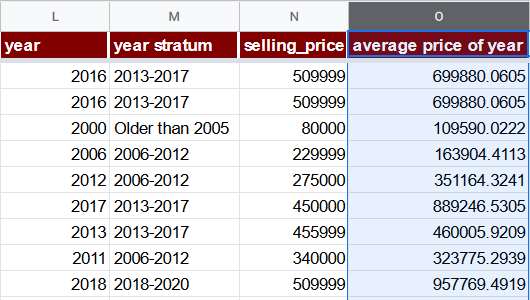
Учёт инфляции и амортизации
Принимая во внимание, что состояние автомобилей ухудшается с возрастом и что новые модели получают всё более совершенные характеристики, разумно ввести своеобразный признак инфляция + амортизация для оценки среднего эффекта этих явлений на конкретную строку.
Один из способов сделать это — добавить в набор данных дополнительные данные, представляющие накопленную инфляцию цен на автомобили в конкретном году, а также коэффициент амортизации для конкретной модели. Однако иногда дополнительные данные могут быть недоступны или их получение может потребовать дополнительных затрат.
Поэтому воспользуемся другим вариантом: столбцом average price of year (O). Его формула будет просто вычислять среднюю цену всех автомобилей, выпущенных в данном году. Поскольку для лет до 2006 года насчитывается менее 100 записей в год, для них мы будем использовать среднюю цену страты «Older than 2005». Отметим, что введение такого признака является формой утечки данных, которую мы обсудим далее на этой странице.
=IF(L2 <= 2005, AVERAGEIF($M$2:$M$8129, "Older than 2005", $N$2:$N$8129), AVERAGEIF($L$2:$L$8129, L2, $N$2:$N$8129))
depreciated max power bhp (AG)
Во всех регрессиях selling_price, выполненных ранее, наиболее значимый коэффициент неизменно присваивался признаку max power bhp.
Тем не менее, поскольку с возрастом характеристики автомобиля ухудшаются, 100 л.с. в паспорте автомобиля 2000 года выпуска могут не означать той же мощности, что и у автомобиля 2020 года с тем же показателем.
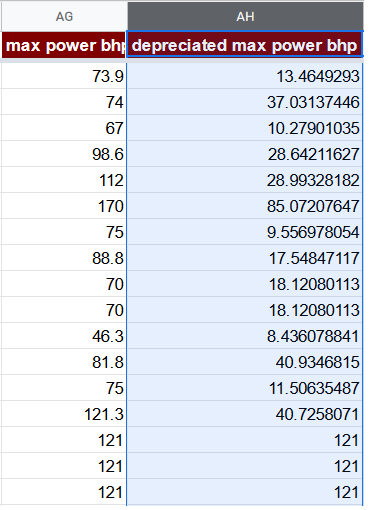
Один из возможных способов скорректировать признак max power bhp в нашем случае — умножить его на average price of year, а затем разделить на максимальное значение average price of year. Смысл этого признака состоит в воспринимаемой ценности max power bhp для автомобиля определённого возраста.
=AG2 * O2 / MAX($O$2:$O$8129)
Подгонка модели с новыми признаками
Корреляционная матрица для selling_price, year и производных признаков выглядит следующим образом:
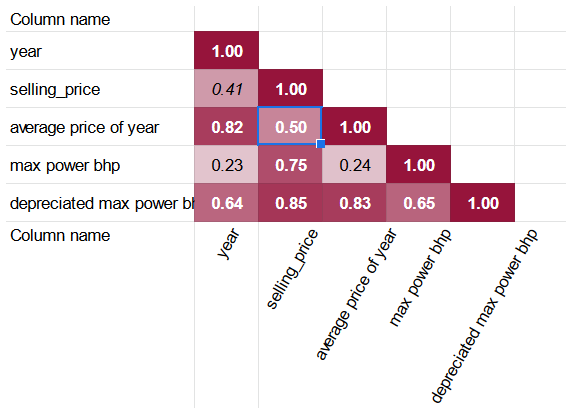
Хорошая новость состоит в том, что столбец depreciated max power bhp имеет более высокий коэффициент корреляции с selling_price, чем исходный max power bhp. Более того, average price of year также коррелирует с selling_price значительнее, чем более простой столбец year.
Добавим эти новые признаки в регрессию, одновременно исключив из неё столбцы year и max power bhp. Столбцы max torque max RPM, petrol и engine cc следует также снять в списке признаков, как было описано выше. Кроме того, необходимо включить параметр 3-Fold Cross-Validation.
Поскольку теперь есть столбец year stratum, его следует задать в качестве столбца страты, а стратификацию установить в значение uniform. Это обеспечит одинаковое число строк из каждой страты в каждом блоке, снижая смещение модели в сторону более новых или более старых автомобилей.
Полная конфигурация регрессии приведена ниже.
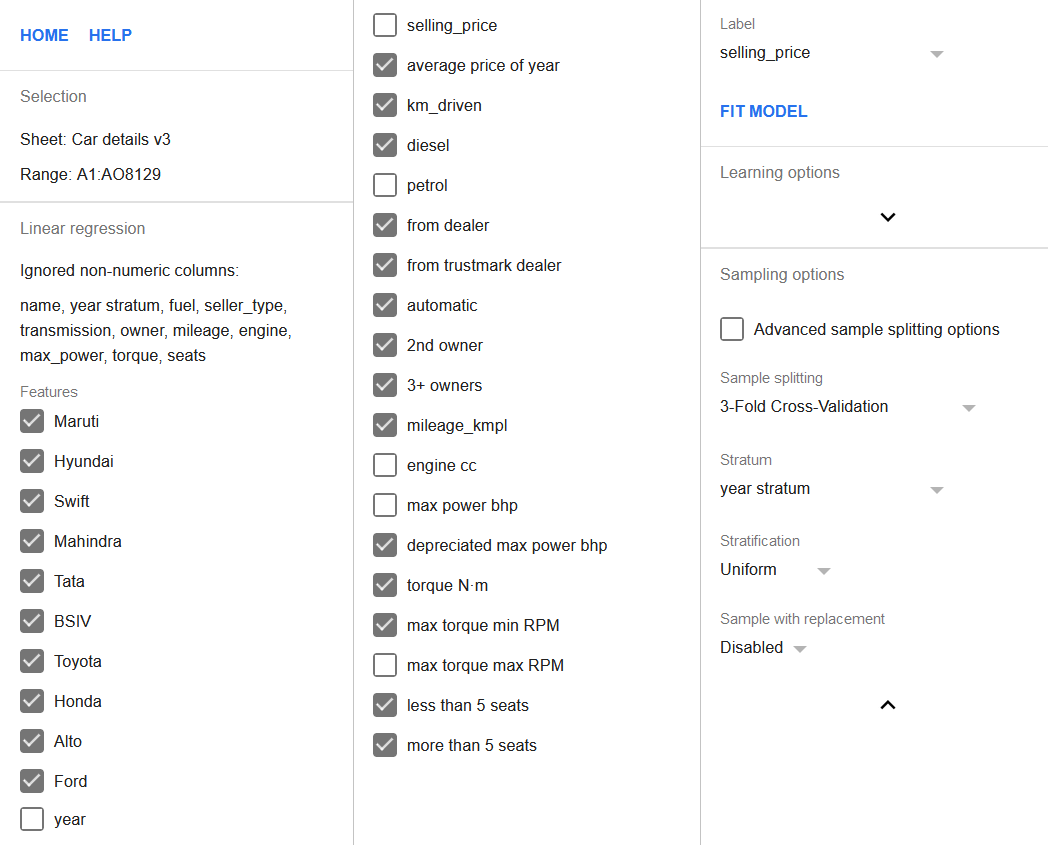
Нажмите кнопку Fit model для выполнения регрессии.

Примечательно, что R² почти достиг своего теоретического максимума — 0,99. Значения RMSE и MAE стали значительно ниже, чем при регрессии с настройками по умолчанию и без каких-либо производных признаков.
Более того, если вставить столбец предсказания и столбец relative error
=ABS((AP2 - N2) / N2) (где N — selling_price,
а AP2 — prediction) и отсортировать по relative error,
то можно видеть, что 19% строк имеют ошибку предсказания не более 10%
от наблюдаемого selling_price, а медианная относительная ошибка
составляет около 28,8%.
Утечка данных
Следует отметить, что вывод признака из зависимой переменной, как это было сделано со столбцом average price of year, вносит утечку данных. Это ситуация, когда метка предсказывается на основе данных, содержащих её саму. Это может осложнить или даже сделать невозможным использование модели на новых данных.
Например, average price of year можно было бы перенести в отдельный
диапазон, а для новых данных использовать функцию LOOKUP для получения
значения признака, поскольку AVERAGEIF неприменима при отсутствии
наблюдаемых значений selling_price. Однако если встретится строка
со значением year, не наблюдавшимся в ходе обучения модели,
найти подходящее значение average price of year окажется невозможным,
и потребуется прибегнуть к наилучшей оценке,
например, к значению для ближайшего по времени года.
Следовательно, улучшенные метрики тонко настроенной модели следует оценивать с осторожностью: в момент предсказания она может работать хуже, если некоторые производные признаки не удастся надёжно получить.
Заключение
Мы попытались продемонстрировать, что параметры тонкой настройки процесса регрессии в TableTorch в совокупности с некоторым конструированием признаков способны привести к более устойчивой и надёжной модели, чем при использовании настроек по умолчанию. Нет предела совершенству, и возможностей для дальнейшего моделирования набора данных об автомобилях ещё немало.
Один из способов улучшить модель — задать ей принципиально другой вопрос. Например, вместо того чтобы пытаться предсказать точное значение selling_price, можно попробовать предсказать, будет ли он выше определённого порога или нет. TableTorch предоставляет подходящий инструмент для построения модели, специализированной на вопросах подобного рода, — логистическую регрессию.
Смотрите также в Википедии:
- Темп обучения
- Районированная выборка
- Перекрёстная проверка
- Утечка данных в машинном обучении (на английском)
- Конструирование признаков
Google, Google Таблицы, Google Workspace и YouTube являются товарными знаками Google LLC. Gaujasoft TableTorch не связан с Google и не одобрен компанией Google.
Свяжитесь с нами!
Спасибо, что используете или рассматриваете TableTorch!
Точно и полно ли эта страница описывает соответствующую функцию? Действительно ли всё работает так, как здесь описано, или вы столкнулись с проблемой? Есть ли у вас предложения по улучшению?
Пожалуйста, свяжитесь с нами, если у вас есть вопросы.