Datenskalierung
Das Skalierungs-Tool von TableTorch skaliert die Daten entsprechend den angegebenen Optionen und fügt ein separates Tabellenblatt mit den Ergebnissen ein. Es unterstützt mehrere Methoden zur Skalierung numerischer Daten, die dabei helfen können, anschließend bessere Ergebnisse mit linearen Regressionen sowie anderen statistischen Analysewerkzeugen zu erzielen.
In den folgenden Abschnitten verwenden wir den Fahrzeugdatensatz als Beispiel und betrachten verschiedene Skalierungsoptionen.
Erste Schritte mit TableTorch
- Installieren Sie TableTorch für Google Tabellen über den Google Workspace Marketplace. Weitere Informationen zur Ersteinrichtung.
- Klicken Sie auf das TableTorch-Symbol
 im rechten Seitenbereich von Google Tabellen.
im rechten Seitenbereich von Google Tabellen.
Überblick
Wählen Sie den gesamten Bereich des Tabellenblatts aus und klicken Sie auf den Skalierungs-Menüpunkt innerhalb von TableTorch.
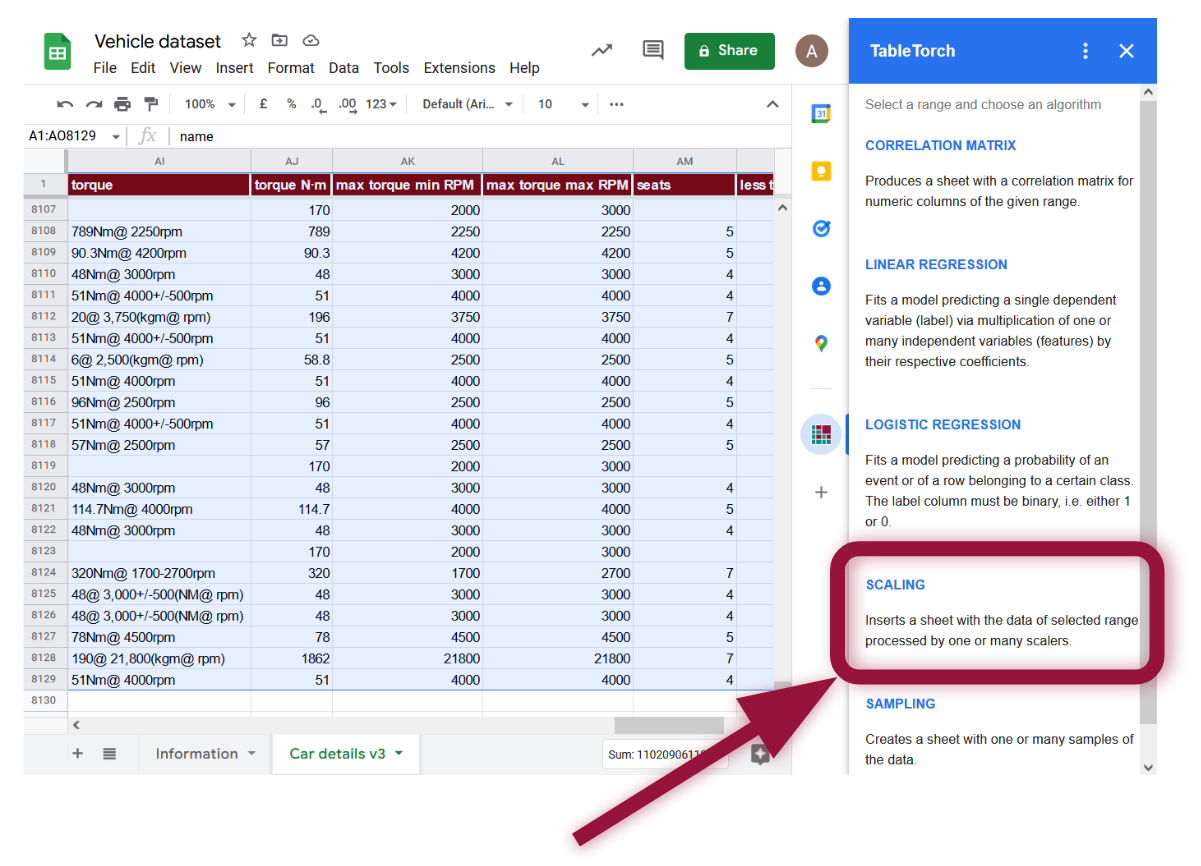
Es erscheint das folgende Menü:
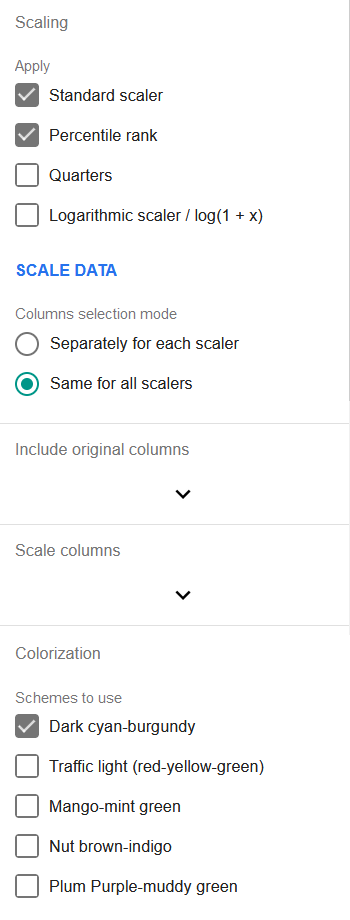
Der erste Abschnitt ermöglicht die Auswahl der anzuwendenden Skalierungsalgorithmen:
-
Standardskalierung: Subtrahiert den Mittelwert des Bereichs vom Zeilenwert und dividiert das Ergebnis durch die Standardabweichung des Bereichs.
v = (v0 - mean(V)) / stdDev(V)Der skalierte Wert lässt sich als Anzahl der Standardabweichungen vom Mittelwert interpretieren. Diese Anzahl kann auch negativ sein, da der skalierte Bereich um Null zentriert wird. Die Standardskalierung wird so häufig vor Regressionen eingesetzt, dass sie direkt in die Regressionen von TableTorch integriert und standardmäßig aktiviert ist. Wird ausschließlich Standardskalierung benötigt, ist es daher nicht nötig, das eigenständige Skalierungs-Tool vor einer Regression zu verwenden — die Skalierung erfolgt direkt im Regressionswerkzeug.
-
Perzentilrang: Ersetzt den Wert durch sein entsprechendes Perzentil in der Menge. TableTorch verwendet dabei Durchschnittsränge, d.h. bei Gleichstand wird der durchschnittliche Rang zugewiesen.
-
Quartile: Fügt drei Spalten Q2, Q3 und Q4 mit einem binären Wert (1 oder 0) ein, der angibt, ob der ursprüngliche Wert im jeweiligen Quartil der Menge lag oder nicht. Q1 fehlt, um hohe Korrelationskoeffizienten zwischen den Merkmalen zu vermeiden und so Regressionen zu erleichtern. Wenn die geplante Datenanalyse keine Regression ist und Q1 benötigt wird, lässt es sich mit einer Formel wie der folgenden hinzufügen:
=IF(AND(Q2Col = 0, Q3Col = 0, Q4Col = 0), 1, 0) -
Logarithmische Skala / log(1 + x): Wendet die angezeigte Formel auf die Werte der Menge an. Das kann für Regressionen nützlich sein, wenn im Voraus bekannt ist, dass die ausgewählten Merkmale eine logarithmische Verteilung aufweisen.
Im nächsten Abschnitt wählen Sie den Spaltenauswahlmodus: ob jeder aktive Skalierer auf dieselben Spalten angewendet wird oder ob die Spalten für jeden Skalierer separat ausgewählt werden.
In den nächsten Abschnitten wählen Sie die ursprünglichen Spalten aus, die in den erzeugten Datensatz aufgenommen werden sollen, sowie die Spalten, die durch die Skalierer verarbeitet werden.
Der letzte Abschnitt des Werkzeugs, Farbgebung, ermöglicht es, ein oder mehrere Farbschemas zu aktivieren, die auf die Spalten mit skalierten Daten angewendet werden. Wenn mehr als ein Schema aktiviert ist, wechseln sie sich ab, sodass es einfacher wird, die Spalten im erzeugten Tabellenblatt zu unterscheiden.
Beispiel mit dem Fahrzeugdatensatz
Skalieren wir einige Spalten und sehen, ob sich damit die Regressionsleistung der selling_price-Spalte des Fahrzeugdatensatzes verbessern lässt.
-
Aktivieren Sie Standardskalierung, Perzentilrang und Quartile im Algorithmenabschnitt.
-
Wählen Sie die Option Separat für jeden Skalierer im Spaltenauswahlmodus.
-
Wählen Sie name und selling_price im Originalspalten-Menü.
- Wählen Sie die folgenden Spalten für Standardskalierung:
- year
- max power bhp
- max torque min RPM
- Für Perzentilrang:
- mileage_kmpl
- engine cc
- Für Quartile:
- km_driven
- torque N·m
- Klicken Sie auf die Schaltfläche Daten skalieren, um ein Tabellenblatt mit den skalierten Werten zu erzeugen.
Der skalierte Datensatz wird wie der folgende aussehen:
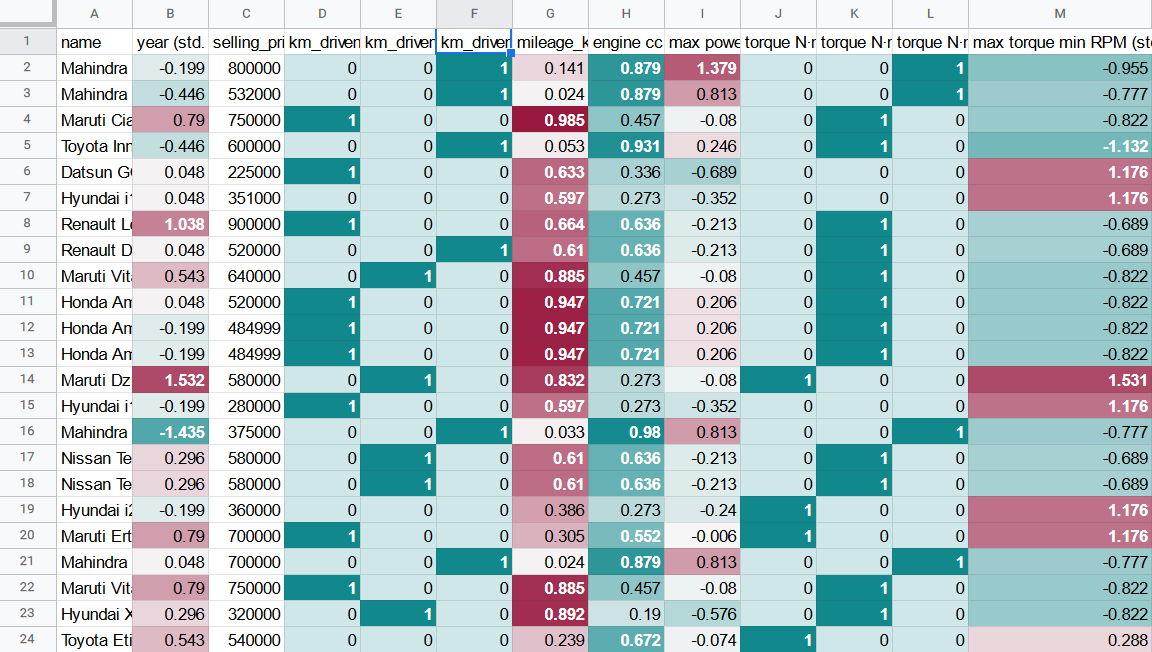
Beachten Sie, dass die skalierten Spalten entsprechend dem Standardfarbschema eingefärbt wurden, was bei der schnelleren visuellen Identifizierung von Datenmustern helfen kann.
Formeln
TableTorch kopiert die Daten als Werte in den resultierenden Datensatz, d.h. Formeln werden nicht übernommen. Das beschleunigt den Vorgang und verhindert, dass Kontingente überschritten werden. Wir gehen davon aus, dass das erzeugte Tabellenblatt nur vorübergehend genutzt wird — etwa für nachfolgende Regressionen oder andere Datenmanipulationen — und nicht für Experimente mit Formeln gedacht ist.
Fazit
Eine Skalierung der Merkmale, die einen möglichst hohen Korrelationskoeffizienten mit der Zielvariable ergibt, kann die Leistung der linearen Regression verbessern.
Siehe auch auf Wikipedia:
- Feature scaling (auf Englisch)
- Feature engineering (auf Englisch)
- Standardisierung (Statistik)
- Percentile rank (auf Englisch)
- Logarithmische Darstellung
Google, Google Tabellen, Google Workspace und YouTube sind Marken von Google LLC. Gaujasoft TableTorch ist nicht mit Google verbunden und wird nicht von Google unterstützt.
Ihr Feedback ist uns wichtig!
Vielen Dank, dass Sie TableTorch verwenden oder in Betracht ziehen!
Beschreibt diese Seite die Funktion korrekt und verständlich? Funktioniert sie tatsächlich so, wie hier beschrieben, oder gibt es ein Problem? Haben Sie Verbesserungsvorschläge?
Bei Fragen können Sie sich jederzeit gerne an uns wenden.
- E-Mail: ___________
- Facebook-Seite
- Twitter-Profil