Daten-Sampling
Die Daten-Sampling-Funktion von TableTorch liest die Daten des ausgewählten Bereichs und fügt ein neues Tabellenblatt ein, das separate Stichproben der Originaldaten enthält, wobei Zeilen gemäß den angegebenen Optionen ausgewählt werden.
Sie kann für folgende Zwecke verwendet werden:
- Aufteilen der Daten in separate Train-Test-Sätze oder eine Anzahl von gleich großen Sätzen, die für die K-Fold-Kreuzvalidierung nützlich sind.
- Randomisieren der Zeilenreihenfolge.
- Geschichtetes Sampling:
- Uniform: Jede Aufteilung enthält die gleiche Anzahl von Zeilen pro Schicht.
- Proportional: Der Anteil jeder Schicht ist in jeder Stichprobe derselbe wie im ursprünglichen Datensatz.
- Sampling mit Ersetzung: Jede Zeile hat die gleiche Wahrscheinlichkeit, in die resultierende Aufteilung aufgenommen zu werden. Die Anzahl der Zeilen kann größer sein als im ursprünglichen Datensatz, da dieselbe Zeile mehrfach in einer Stichprobe erscheinen kann.
Die im Sampling-Panel verfügbaren Techniken sind dieselben wie bei der linearen Regression und logistischen Regression. Der zugrunde liegende Algorithmus ist ebenfalls derselbe. Daher kann Sampling nützlich sein, um vor einer Regression visuell zu überprüfen, wie die Daten aufgeteilt werden, oder um die Stichproben weiter zu untersuchen.
In den folgenden Abschnitten wenden wir die einzelnen Optionen auf den Fahrzeugdatensatz an.
- Erste Schritte mit TableTorch
- Train-Test-Aufteilung
- Geschichtete 3-Fold-Kreuzvalidierungs-Aufteilung
- Sampling mit Ersetzung
- Formeln
Erste Schritte mit TableTorch
- Installieren Sie TableTorch für Google Tabellen über den Google Workspace Marketplace. Weitere Informationen zur Ersteinrichtung.
- Klicken Sie auf das TableTorch-Symbol
 im rechten Seitenbereich von Google Tabellen.
im rechten Seitenbereich von Google Tabellen.
Train-Test-Aufteilung
Wählen Sie den gesamten Datensatz aus und klicken Sie auf die Schaltfläche Sampling im TableTorch-Menü.
Ein Panel mit Sampling-Optionen erscheint:
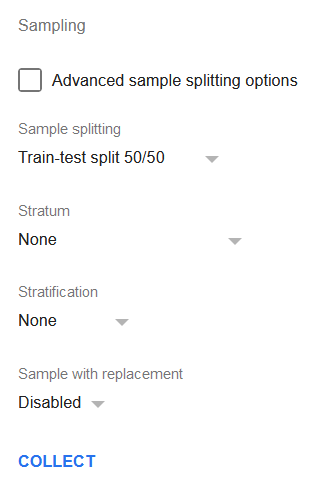
Klicken Sie auf die Schaltfläche Collect. TableTorch fügt daraufhin ein neues Tabellenblatt mit zwei Stichproben der Daten ein, die jeweils aus der Hälfte der Zeilen des ursprünglichen Datensatzes bestehen.
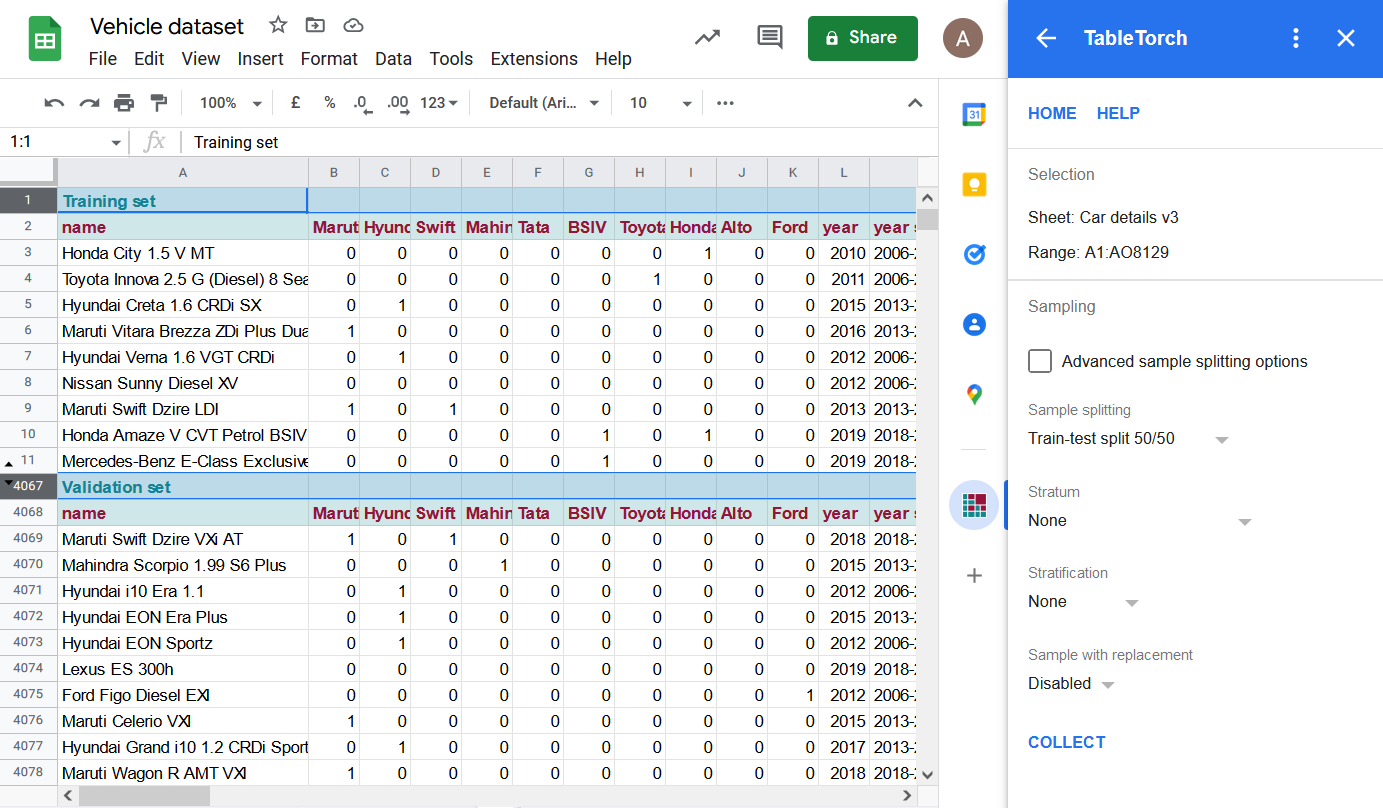
Die Zeilen 12..4066 sind im obigen Screenshot ausgeblendet, um zu zeigen, dass das resultierende Blatt zwei separate Datensätze mit identischer Spaltenstruktur, eine Kopfzeile mit der Bezeichnung des Satzes sowie eine zusätzliche Zeile mit den Spaltennamen enthält.
Sampling mit Ersetzung wurde nicht verwendet, daher enthält jeder Satz nur eindeutige Zeilen aus dem ursprünglichen Datensatz.
Geschichtete 3-Fold-Kreuzvalidierungs-Aufteilung
Versuchen wir eine 3-Fold-Kreuzvalidierungs-Aufteilung mit year stratum (siehe Seite Feinabstimmung von Regressionen für die Formel) als Schichtspalte und geschichtetem uniformem Sampling. Die vollständigen Optionen sind im Bild unten dargestellt.
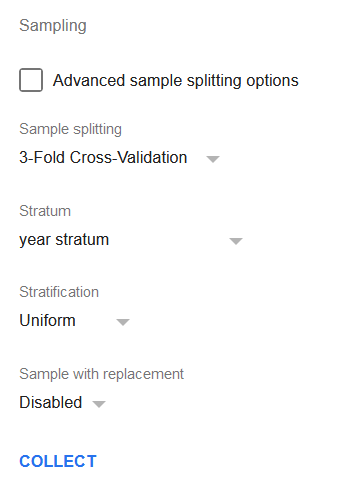
Klicken Sie auf die Schaltfläche Collect, um das Sampling durchzuführen.
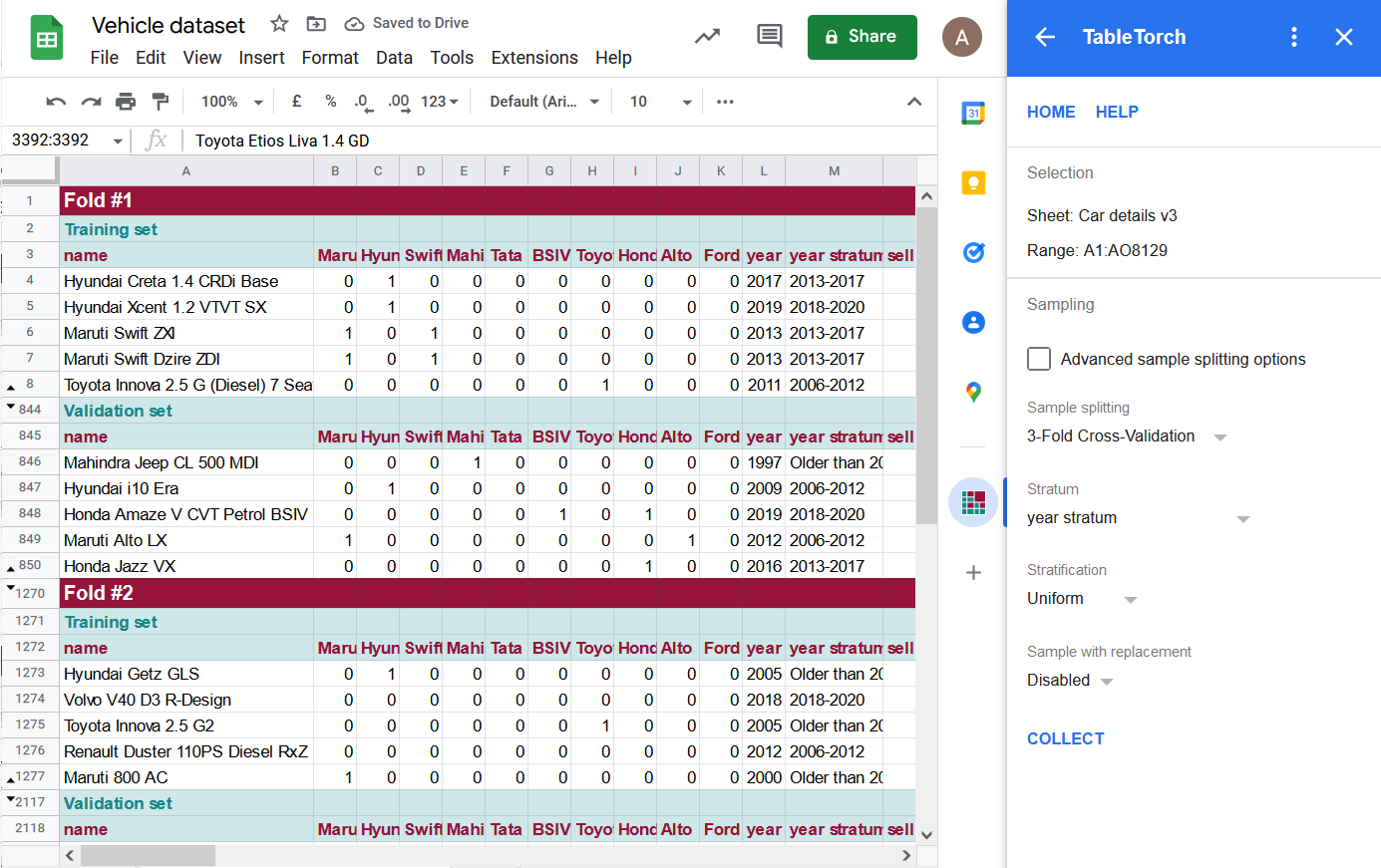
Einige der Zeilen sind im obigen Bild ausgeblendet, damit die Kopfzeilen der Falten und ihrer jeweiligen Sätze sichtbar sind.
TableTorch hat 3 Falten erzeugt. Jede davon umfasst einen Trainingssatz mit zwei Dritteln der Daten sowie einen Validierungssatz, der jeweils ein eindeutiges Drittel des ursprünglichen Datensatzes enthält.
Jede Schicht, die durch die Spalte year stratum definiert ist, ist in jedem Trainings- und Validierungssatz gleichmäßig vertreten, d.h. die Anzahl der Zeilen sollte gleich sein. Eine leichte Abweichung kann auftreten, wenn die Anzahl der Zeilen nicht gleichmäßig durch den k-Parameter der Kreuzvalidierung (also 3, 5 oder 10) teilbar ist.
Sampling mit Ersetzung
Ersetzung ermöglicht geschichtetes Sampling, ohne dass unterrepräsentierte Schichten zum Problem werden.
Stellen Sie sich einen Datensatz mit 200 Zeilen vor, wobei 40 Zeilen zur Schicht A gehören und 160 zur Schicht B. Geschichtetes uniformes Sampling sollte einen Datensatz mit identischer Anzahl von Zeilen für jede Schicht erzeugen. Daher kann es mit Standardeinstellungen nur einen Datensatz mit 80 Zeilen erzeugen — 40 aus A und 40 aus B. Jede statistische Analyse, die an der erzeugten Stichprobe durchgeführt werden soll, verliert 120 bzw. 75 % der Zeilen, die zu Schicht B gehören, was einen erheblichen Signalverlust darstellt und die Validität der Analyse beeinträchtigen kann.
Sampling mit Ersetzung ist darauf ausgelegt, diesen Mangel zu beheben. Es zieht eine vorgegebene Anzahl an Zeilen zufällig aus dem ursprünglichen Satz. Mit Ersetzung kann geschichtetes uniformes Sampling somit einen Datensatz mit 160 oder mehr Zeilen für beide Schichten erzeugen. Allerdings werden einige dieser Zeilen Duplikate sein, daher eignet sich diese Art von Sampling nur für bestimmte statistische Analysen, z. B. lineare Regressionen.
Wenn Ersetzung aktiviert ist, verwendet TableTorch die folgende Heuristik, um die Anzahl der auszuwählenden Zeilen zu berechnen:
- Sei n die Anzahl der Zeilen im ursprünglichen Datensatz geteilt durch die Anzahl der Schichten. Bei einem Datensatz mit 240 Zeilen und 3 Schichten ist n beispielsweise gleich 80.
- Wenn der ursprüngliche Datensatz weniger als 1000 Zeilen hat, wählt TableTorch ein Vielfaches von n Zeilen aus, um die Wahrscheinlichkeit zu erhöhen, dass alle ursprünglichen Zeilen in den Datensatz gelangen. Wenn beispielsweise n gleich 80 ist, wählt TableTorch je nach Anzahl der Spalten und anderen Umständen wahrscheinlich mindestens 200 Zeilen für jede Schicht aus.
- Andernfalls wählt TableTorch n Zeilen pro Schicht aus. Das kann dazu führen, dass einige Zeilen in der resultierenden Stichprobe fehlen, ist aber notwendig, um die Wahrscheinlichkeit zu verringern, die maximale Ausführungszeit zu überschreiten oder versehentlich mehr Zellen einzufügen, als das Limit von 5 Millionen Zellen in Google Tabellen erlaubt.
Formeln
TableTorch kopiert die Daten als Werte in den resultierenden Datensatz, d.h. Formeln werden nicht übernommen. Das beschleunigt den Vorgang und verhindert, dass Kontingente überschritten werden. Wir gehen davon aus, dass das erzeugte Blatt nur vorübergehend genutzt wird — etwa für nachfolgende Regressionen oder andere Datenmanipulationen — und nicht für Experimente mit Formeln gedacht ist.
Siehe auch auf Wikipedia:
Google, Google Tabellen, Google Workspace und YouTube sind Marken von Google LLC. Gaujasoft TableTorch ist nicht mit Google verbunden und wird nicht von Google unterstützt.
Ihr Feedback ist uns wichtig!
Vielen Dank, dass Sie TableTorch verwenden oder in Betracht ziehen!
Beschreibt diese Seite die Funktion korrekt und verständlich? Funktioniert sie tatsächlich so, wie hier beschrieben, oder gibt es ein Problem? Haben Sie Verbesserungsvorschläge?
Bei Fragen können Sie sich jederzeit gerne an uns wenden.
- E-Mail: ___________
- Facebook-Seite
- Twitter-Profil