Lineare Regression
Die lineare Regression passt ein Modell an, das eine einzelne abhängige Variable (Zielvariable) vorhersagt, indem es eine oder mehrere unabhängige Variablen (Merkmale) mit den jeweiligen Koeffizienten multipliziert.
TableTorch bietet einen umfangreichen Funktionsumfang für Regressionen:
- sowohl die Methode der gewöhnlichen als auch der gewichteten kleinsten Quadrate zur Schätzung der Koeffizienten;
- Trainings-/Validierungs-Aufteilung;
- k-fache Kreuzvalidierung;
- stratifiziertes Sampling;
- Sampling mit Ersetzung.
Nach dem Anpassen des Modells kann TableTorch eine Vorhersagespalte mit einer Formel zur Schätzung der Zielvariable einfügen sowie ein Regressionszusammenfassungsblatt erstellen. Die Formel kann dann direkt auf beliebige andere Daten angewendet werden, die dieselben Merkmale (Spalten) enthalten, um die Zielvariable zu schätzen.
In den folgenden Abschnitten werden wir die einfachste Regression anpassen, die die Spalte selling_price des Fahrzeugdatensatzes vorhersagt. Weitere Informationen zu verschiedenen Lern- und Sampling-Optionen finden Sie auf der Seite Feinabstimmung von Regressionen.
- Erste Schritte mit TableTorch
- Anpassen mit Standardeinstellungen
- Vorhersagespalte einfügen
- Zusammenfassungsblatt hinzufügen
- Fazit
Erste Schritte mit TableTorch
- Installieren Sie TableTorch für Google Tabellen über den Google Workspace Marketplace. Weitere Informationen zur Ersteinrichtung.
- Klicken Sie auf das TableTorch-Symbol
 im rechten Seitenbereich von Google Tabellen.
im rechten Seitenbereich von Google Tabellen.
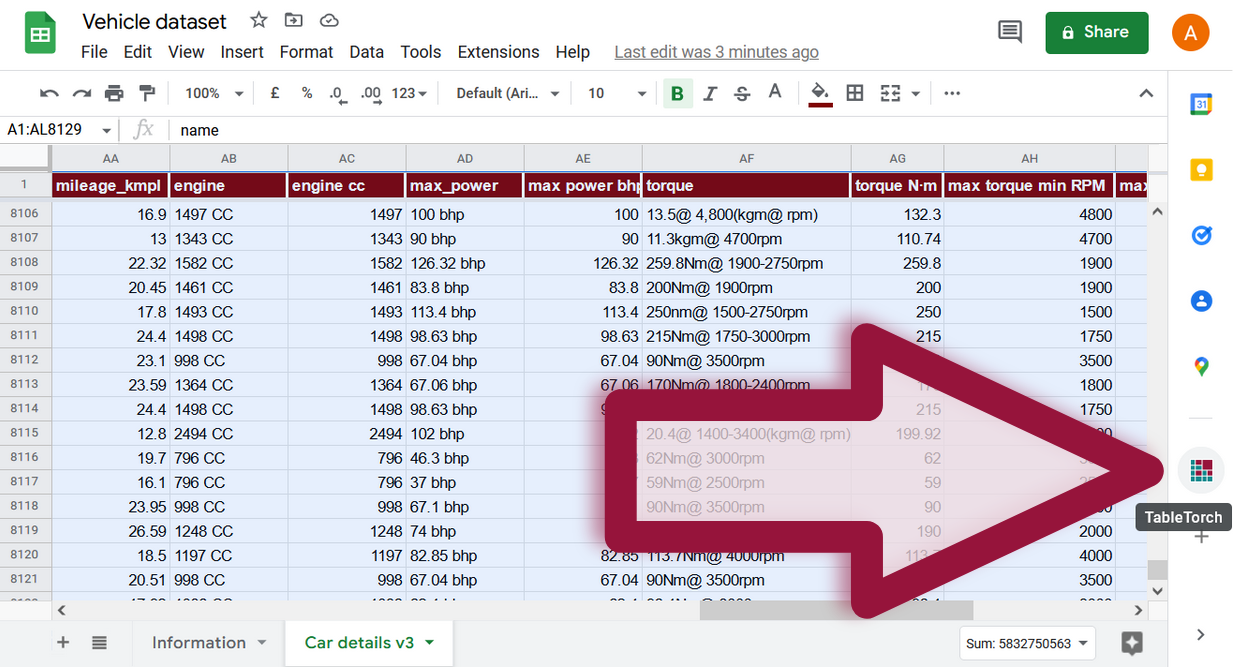
Anpassen mit Standardeinstellungen
Wählen Sie den gesamten Bereich des Blattes aus und klicken Sie auf den Menüpunkt Linear regression in TableTorch.
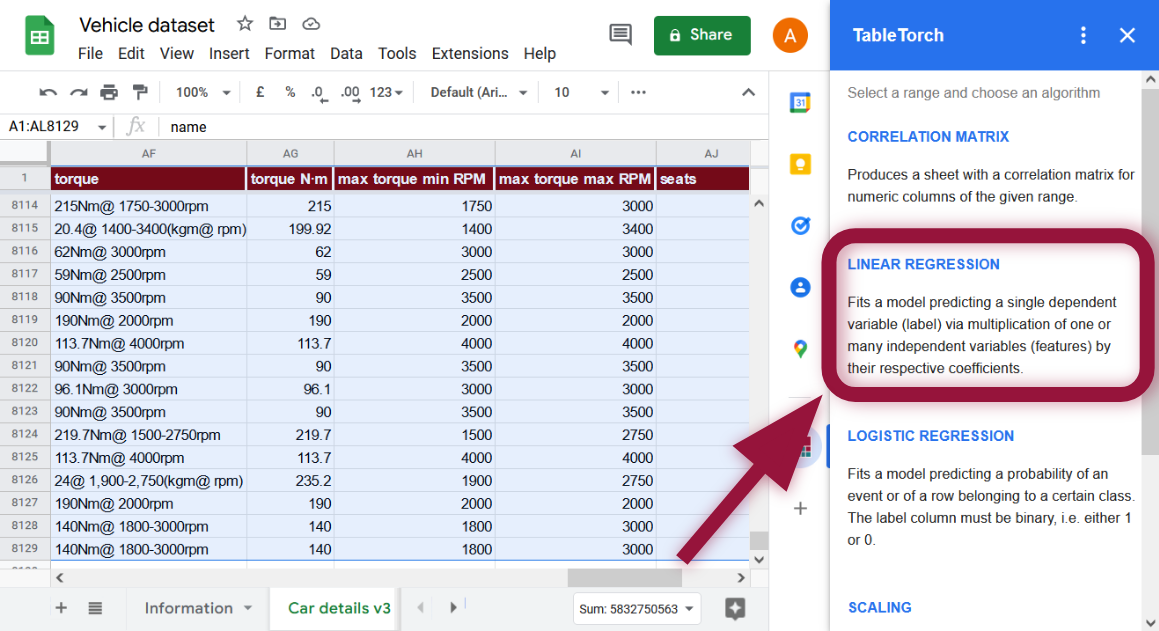
Nicht-numerische Spalten werden automatisch herausgefiltert.
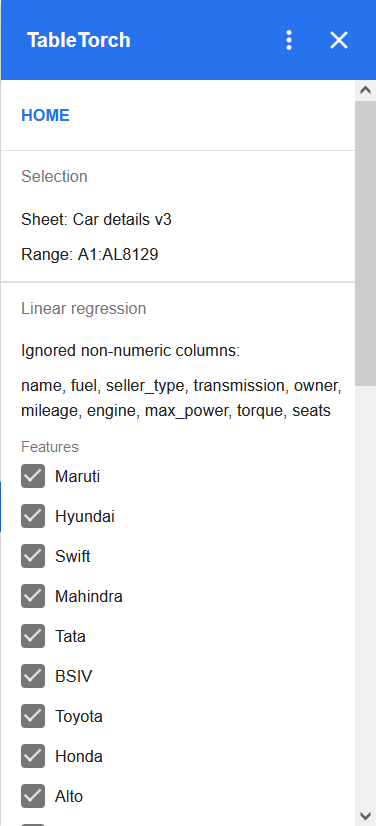
Die letzte Spalte more than 5 seats ist standardmäßig als Zielvariable
ausgewählt. Da unser Ziel ist, den Wert einer anderen Spalte vorherzusagen,
ändern Sie die Zielvariable wie folgt auf selling_price:

Es spielt keine Rolle, ob selling_price in der Merkmalsliste
angekreuzt ist oder nicht: Da diese Spalte als Zielvariable ausgewählt ist,
schließt TableTorch sie automatisch aus der Merkmalsliste aus.
Klicken Sie auf die Schaltfläche Fit model.
![]()
Es erscheint das folgende Ergebnispanel:
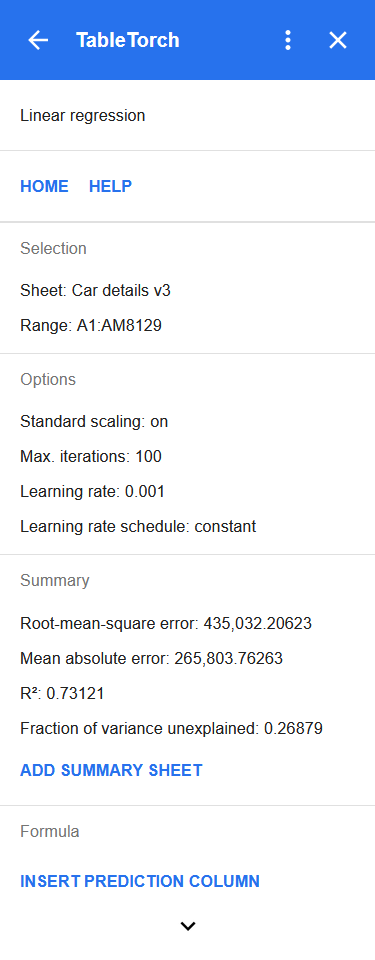
Das Panel zeigt den ausgewählten Bereich, die wichtigsten Lernoptionen und vor allem die zentralen Kennzahlen der Lernzusammenfassung:
- Quadratmittel-Fehler (RMSE) und Mittlerer absoluter Fehler (MAE): am häufigsten verwendete Metriken zur Messung der durchschnittlichen Abweichung zwischen Vorhersagen und beobachteten Werten.
- R² (R-Quadrat): auch Bestimmtheitsmaß genannt; der Anteil der Variation der abhängigen Variable, den die Regression erfolgreich aus der/den unabhängigen Variable(n) vorhersagen konnte.
- Anteil der unerklärten Varianz: ist gleich
1 - R²und stellt den Anteil der Variation dar, den die Regression nicht erfolgreich aus der/den unabhängigen Variable(n) schätzen konnte.
Schauen wir uns die erstellte Zusammenfassung genauer an.

Beachten Sie, dass wiederholte Regressionen auf demselben Bereich unterschiedliche Ergebnisse liefern können, da TableTorch die Daten vor und zwischen den Iterationen mischt, um die Robustheit des angepassten Modells zu verbessern.
Der MAE liegt bei über 260.000, das sind etwa 41 % des durchschnittlichen Verkaufspreises von 638.272 oder mehr als die Hälfte des Medianpreises von 450.000. Je nach unseren Zielen kann das akzeptabel sein oder nicht — noch ist unbekannt, welche Zeilen den MAE so weit nach oben treiben; möglicherweise liegt es nur an einigen wenigen teuren Luxusautos.
R² liegt bei etwa 0,73, was wiederum je nach Umständen akzeptabel sein kann. Für den ersten Versuch ist das auf jeden Fall nicht schlecht, denn wir haben weder Spalten anhand der Korrelationsmatrix-Analyse ausgeschlossen noch Ausreißer entfernt oder die Lern- und Sampling-Optionen feinabgestimmt.
Je besser die Regression ist, desto niedriger sollten RMSE und MAE und desto höher sollte R² sein. Diese Kennzahlen erfassen jedoch verschiedene Aspekte der Regression und müssen gemeinsam betrachtet werden, wenn über die Akzeptanz des Modells entschieden werden soll.
Auf diese weiterführenden Möglichkeiten gehen wir im Artikel Feinabstimmung von Regressionen ein.
Schauen wir uns zunächst an, wie das angepasste Modell verwendet wird, bevor wir uns mit der Feinabstimmung befassen.
Vorhersagespalte einfügen
Am unteren Rand des Regressionszusammenfassungspanels befindet sich der Abschnitt Formula mit der Schaltfläche Insert prediction column.

Klicken Sie darauf, um nach dem analysierten Bereich eine Spalte mit einer Formel
einzufügen, die den Wert der Spalte selling_price schätzt.
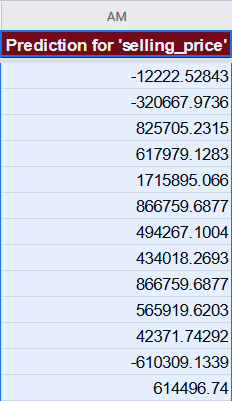
Für die erste Zeile sieht die Formel wie folgt aus:
=639827.171051266 + ((B2 - 0.301181102362204) / 0.458799459127852) * -13624.7005345943 + ((C2 - 0.174089566929133) / 0.379209812049647) * -78332.2214570537 + ((D2 - 0.0962106299212598) / 0.294898023096581) * -40904.9165485197 + ((E2 - 0.0949803149606299) / 0.293205783883989) * -54328.4653464246 + ...
Da die Standardskalierung standardmäßig aktiviert ist, hat TableTorch das Modell auf skalierten Daten trainiert, daher enthält die Vorhersageformel auch die Skalierungsanweisungen und hat das folgende Format:
=modelIntercept +
((Col1 - Col1Mean) / Col1StdDev) * Col1Coefficient +
((Col2 - Col2Mean) / Col2StdDev) * Col2Coefficient +
... +
((ColN - ColNMean) / ColNStdDev) * ColNCoefficient
Auf der Vorhersagespalte lassen sich nun zahlreiche Analysen durchführen, z. B. die Auswertung der Fehler für bestimmte Schichten, um die Stärken und Schwächen des Modells besser zu verstehen oder um Anpassungen an Daten und Lernoptionen abzuleiten, die zu einem besseren Modell führen.
Wird das Modell als akzeptabel eingestuft, lässt es sich auf neue Daten anwenden, indem die Formel in einen anderen Bereich mit identischer Spaltenstruktur kopiert wird. Wenn wir beispielsweise neue Fahrzeugdaten ohne bekannten Verkaufspreis vorliegen haben, können wir den Preis mit dem Modell schätzen.
Zusammenfassungsblatt hinzufügen
Eine weitere nützliche Funktion des Regressionsergebnispanels ist die Schaltfläche Add summary sheet im Abschnitt Summary.
![]()
Ein Klick darauf fügt ein neues Blatt mit einer detaillierteren Zusammenfassung der Regression ein.
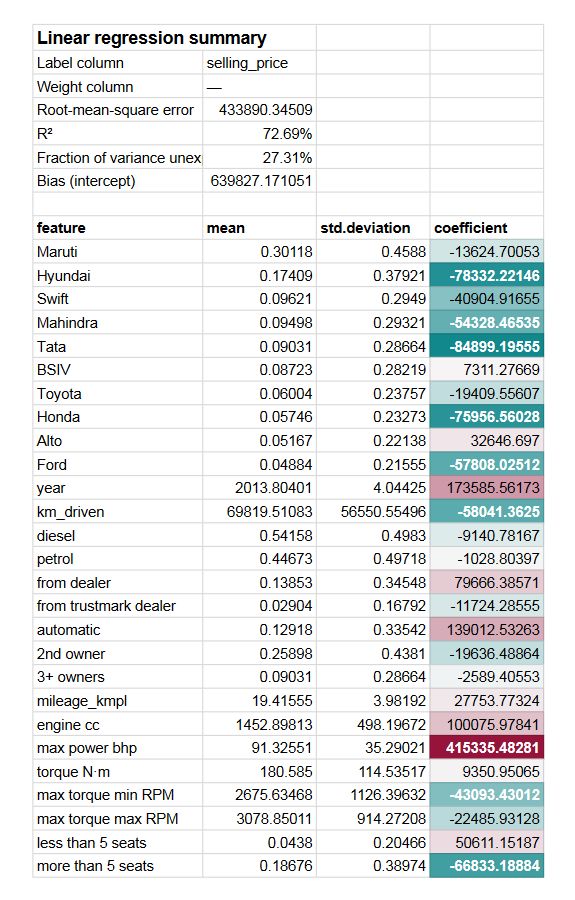
Zusätzlich zu den Metriken wie R² und RMSE, die auch im Regressionsergebnispanel vorhanden sind, zeigt das Zusammenfassungsblatt:
- Bias des Modells (Intercept). Dies ist der Wert, der nicht allein durch unabhängige Variablen erklärt werden konnte.
- Den Koeffizienten jedes Merkmals und, falls Standardskalierung aktiviert war, auch die jeweiligen Mittelwerte und Standardabweichungen. Die Koeffizienten sind so hervorgehoben, dass sich die bedeutendsten schnell erkennen lassen.
Fazit
TableTorch erstellt schon mit Standardeinstellungen ein brauchbares Modell. Es bietet darüber hinaus jedoch viele hilfreiche Optionen zur Verbesserung der Regressionsleistung. Werfen Sie auch einen Blick auf die Seite Feinabstimmung von Regressionen, um diese Optionen kennenzulernen.
Siehe auch:
- Artikel zur linearen Regression auf Wikipedia
- Artikel zur Methode der kleinsten Quadrate auf Wikipedia
Google, Google Tabellen, Google Workspace und YouTube sind Marken von Google LLC. Gaujasoft TableTorch ist nicht mit Google verbunden und wird nicht von Google unterstützt.
Ihr Feedback ist uns wichtig!
Vielen Dank, dass Sie TableTorch verwenden oder in Betracht ziehen!
Beschreibt diese Seite die Funktion korrekt und verständlich? Funktioniert sie tatsächlich so, wie hier beschrieben, oder gibt es ein Problem? Haben Sie Verbesserungsvorschläge?
Bei Fragen können Sie sich jederzeit gerne an uns wenden.
- E-Mail: ___________
- Facebook-Seite
- Twitter-Profil