Масштабирование данных
Инструмент Масштабирование TableTorch масштабирует данные в соответствии с указанными параметрами и вставляет отдельный лист с результатами. Он поддерживает несколько методов масштабирования числовых данных, которые могут помочь достичь лучших результатов с линейными регрессиями, а также с другими инструментами статистического анализа.
Мы будем использовать набор данных об автомобилях в качестве примера и рассмотрим различные параметры масштабирования в следующих разделах.
Запуск TableTorch
- Установите TableTorch для Google Таблиц через Google Workspace Marketplace. Подробнее о начальной настройке.
- Нажмите на иконку
 TableTorch
на правой боковой панели Google Таблиц.
TableTorch
на правой боковой панели Google Таблиц.
Обзор
Выберите весь диапазон листа и нажмите пункт меню Масштабирование в TableTorch.
Появится следующее меню:
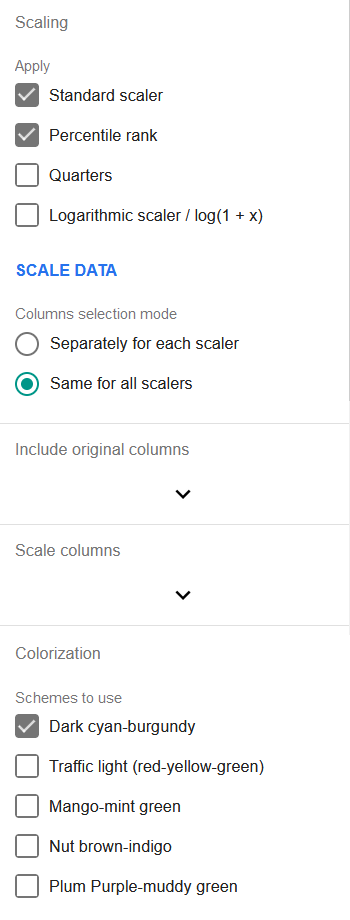
Первый раздел позволяет выбрать алгоритмы масштабирования для применения:
-
Стандартное масштабирование: вычитает среднее значение диапазона из значения строки и делит результат на стандартное отклонение диапазона.
v = (v0 - mean(V)) / stdDev(V)Масштабированное значение можно интерпретировать как количество стандартных отклонений от среднего. Эта величина может быть и отрицательной, поскольку масштабированный диапазон оказывается центрированным вокруг нуля. Стандартное масштабирование настолько часто применяется перед регрессиями, что встроено прямо в инструмент регрессии TableTorch и включено по умолчанию. Поэтому отдельно запускать Масштабирование перед регрессией не нужно, если других методов масштабирования не требуется — достаточно соответствующего флажка в самом инструменте регрессии.
-
Процентильный ранг: заменяет значение его соответствующим процентилем в наборе. Используется дробное ранжирование, т.е. одинаковым значениям присваивается их средний ранг.
-
Квартили: вставляет три столбца Q2, Q3 и Q4 с бинарным значением (1 или 0), указывающим, лежит ли исходное значение в указанной четверти набора или нет. Q1 отсутствует, чтобы избежать высоких коэффициентов корреляции между признаками и тем самым облегчить регрессии. Если планируемый анализ данных не является регрессией и Q1 нужен, его легко добавить формулой вида:
=IF(AND(Q2Col = 0, Q3Col = 0, Q4Col = 0), 1, 0) -
Логарифмическое масштабирование / log(1 + x): применяет показанную формулу к значениям набора. Это может быть полезно для регрессий, когда заранее известно, что указанные признаки имеют логарифмическое распределение.
В следующем разделе выбирается режим работы со столбцами: применять ли все отмеченные методы к одному и тому же набору столбцов или указывать столбцы отдельно для каждого метода.
Следующие два или более раздела позволяют выбрать исходные столбцы для включения в созданный набор данных, а также столбцы, которые будут обработаны методами масштабирования.
Последний раздел инструмента, Раскрашивание, позволяет включить одну или несколько цветовых схем для применения к столбцам с масштабированными данными. Если включено более одной схемы, они будут чередоваться, чтобы было легче различать столбцы в созданном листе.
Пример с набором данных об автомобилях
Давайте масштабируем несколько столбцов и посмотрим, может ли это помочь улучшить качество регрессии для столбца selling_price из набора данных об автомобилях.
-
Отметьте стандартное масштабирование, процентильный ранг и квартили в разделе алгоритмов.
-
Выберите параметр Отдельно для каждого метода в режиме выбора столбцов.
-
Выберите name и selling_price в меню исходных столбцов.
- Выберите следующие столбцы для стандартного масштабирования:
- year
- max power bhp
- max torque min RPM
- Для процентильного ранга:
- mileage_kmpl
- engine cc
- Для квартилей:
- km_driven
- torque N·m
- Нажмите кнопку Масштабировать данные, чтобы создать лист с масштабированными значениями.
Масштабированный набор данных будет выглядеть следующим образом:
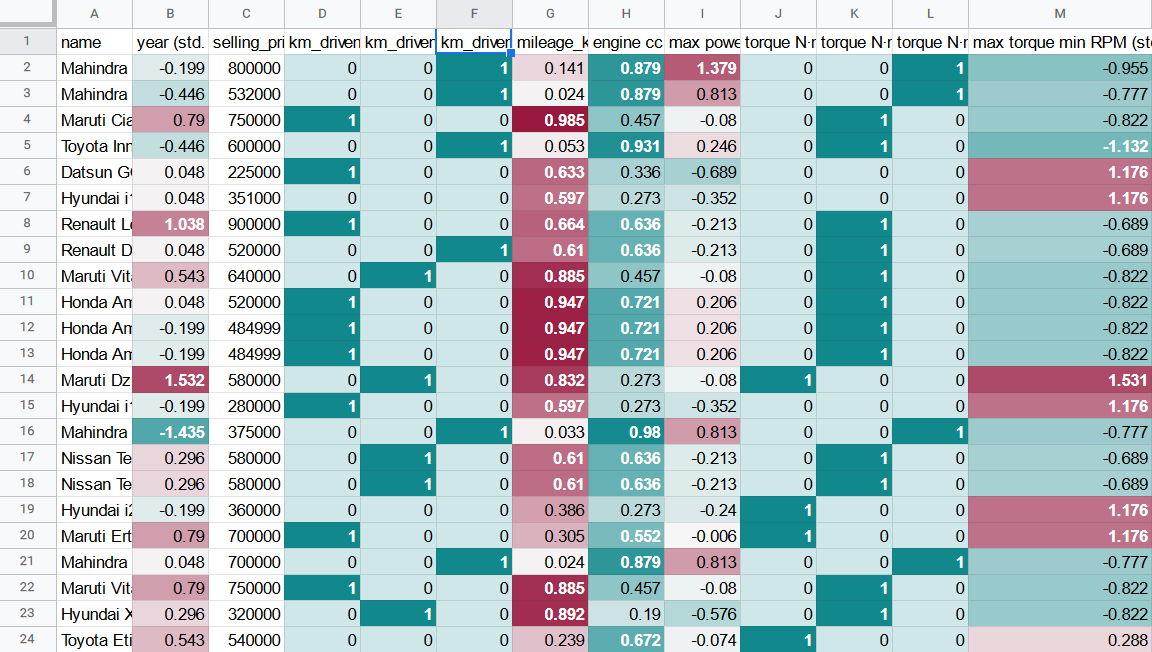
Обратите внимание, что масштабированные столбцы были раскрашены в соответствии с цветовой схемой по умолчанию, что может помочь с более быстрой визуальной идентификацией паттернов в данных.
Формулы
TableTorch копирует данные в результирующий набор по значениям, т.е. формулы не копируются. Это сделано для ускорения процесса и избежания превышения квот. Предполагается, что созданный лист имеет временный характер и полезен для последующих регрессий или других манипуляций с данными, а не для экспериментов с формулами.
Заключение
Масштабирование признаков способом, который обеспечивает максимальный коэффициент корреляции с меткой, может помочь улучшить качество линейной регрессии.
Смотрите также в Википедии:
- Масштабирование признаков (на английском)
- Конструирование признаков
- Z-оценка
- Процентильный ранг (на английском)
- Логарифмическая шкала
Google, Google Таблицы, Google Workspace и YouTube являются товарными знаками Google LLC. Gaujasoft TableTorch не связан с Google и не одобрен компанией Google.
Свяжитесь с нами!
Спасибо, что используете или рассматриваете TableTorch!
Точно и полно ли эта страница описывает соответствующую функцию? Действительно ли всё работает так, как здесь описано, или вы столкнулись с проблемой? Есть ли у вас предложения по улучшению?
Пожалуйста, свяжитесь с нами, если у вас есть вопросы.